**번역본뉴스입니다. 오역이 있을수 있습니다.
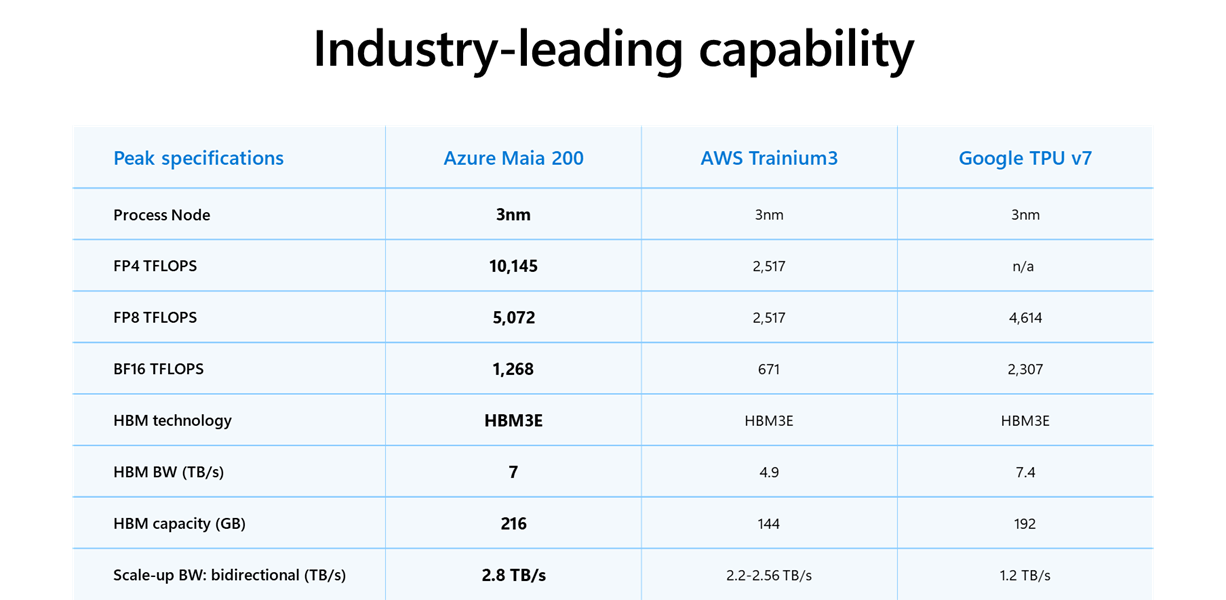
오늘 우리는 AI 토큰 생성의 경제성을 획기적으로 개선하기 위해 설계된 혁신적인 추론 가속기인 Maia 200을 소개하게 되어 자랑스럽게 생각합니다. Maia 200은 AI 추론의 강자입니다. TSMC의 3nm 공정을 기반으로 제작된 이 가속기는 네이티브 FP8/FP4 텐서 코어, 7 TB/s 속도의 216GB HBM3e 및 272MB 온칩 SRAM을 갖춘 재설계된 메모리 시스템, 그리고 거대 모델에 데이터를 끊임없이 공급하여 빠르고 높은 가동률을 유지하는 데이터 이동 엔진을 탑재하고 있습니다. 이로써 Maia 200은 모든 하이퍼스케일러 중 가장 성능이 뛰어난 퍼스트 파티 실리콘이 되었으며, 아마존 Trainium 3세대보다 3배 높은 FP4 성능과 구글 TPU 7세대보다 높은 FP8 성능을 제공합니다. 또한 Maia 200은 마이크로소프트가 배포한 역대 가장 효율적인 추론 시스템으로, 현재 우리 함대(fleet) 내의 최신 세대 하드웨어보다 달러당 성능이 30% 더 우수합니다.
Maia 200은 우리의 이기종 AI 인프라의 일부로서 OpenAI의 최신 GPT-5.2 모델을 포함한 다중 모델을 지원하며, 마이크로소프트 파운드리와 마이크로소프트 365 코파일럿에 달러당 성능 우위를 제공할 것입니다. 마이크로소프트 슈퍼인텔리전스 팀은 차세대 자체 모델을 개선하기 위한 합성 데이터 생성 및 강화 학습에 Maia 200을 사용할 예정입니다. 합성 데이터 파이프라인 사례의 경우, Maia 200의 독특한 설계는 고품질의 도메인 특화 데이터를 생성하고 필터링하는 속도를 가속화하여, 더 신선하고 타겟팅된 신호로 하류(downstream) 학습에 기여합니다.
Maia 200은 아이오와주 디모인 근처의 미국 중부 데이터센터 리전에 배포되었으며, 애리조나주 피닉스 근처의 미국 서부 3 리전이 그 뒤를 이을 예정이고 향후 다른 리전들도 추가될 것입니다. Maia 200은 Azure와 원활하게 통합되며, 우리는 Maia 200을 위한 모델 구축 및 최적화 도구 세트인 Maia SDK의 프리뷰를 공개합니다. 여기에는 PyTorch 통합, Triton 컴파일러 및 최적화된 커널 라이브러리, 그리고 Maia의 저수준 프로그래밍 언어 접근 권한 등 모든 기능이 포함되어 있습니다. 이를 통해 개발자는 필요한 경우 미세한 제어를 할 수 있는 동시에, 이기종 하드 가속기 간에 쉬운 모델 이식이 가능해집니다.
AI 추론을 위해 설계됨
TSMC의 최첨단 3나노미터 공정으로 제조된 각각의 Maia 200 칩은 1,400억 개 이상의 트랜지스터를 포함하고 있으며, 대규모 AI 워크로드에 최적화되는 동시에 효율적인 달러당 성능을 제공합니다. Maia 200은 두 가지 측면 모두에서 탁월하도록 제작되었습니다. 저정밀도 연산을 사용하는 최신 모델을 위해 설계되었으며, 각 Maia 200 칩은 750W SoC TDP 범위 내에서 4비트 정밀도(FP4)에서 10페타플롭스 이상, 8비트 정밀도(FP8)에서 5페타플롭스이상의 성능을 제공합니다. 실질적으로 Maia 200은 오늘날 가장 큰 모델들을 여유롭게 실행할 수 있으며, 미래의 더 큰 모델들을 위한 충분한 잠재력도 갖추고 있습니다.

중요한 점은, 더 빠른 AI를 위한 요소가 플롭스(FLOPS)뿐만이 아니라는 것입니다. 데이터를 공급하는 것 역시 똑같이 중요합니다. Maia 200은 재설계된 메모리 서브시스템을 통해 이 병목 현상을 해결합니다. Maia 200 메모리 서브시스템은 좁은 정밀도(narrow-precision) 데이터 유형, 특수 DMA 엔진, 온다이(on-die) SRAM 및 고대역폭 데이터 이동을 위한 특수 NoC 패브릭을 중심으로 구성되어 토큰 처리량을 높입니다.
최적화된 AI 시스템
시스템 수준에서 Maia 200은 표준 이더넷을 기반으로 구축된 새로운 2계층 스케일업(scale-up) 네트워크 설계를 도입했습니다. 커스텀 전송 계층과 긴밀하게 통합된 NIC는 독점 패브릭에 의존하지 않고도 성능, 강력한 신뢰성 및 상당한 비용 이점을 실현합니다.
각 가속기는 다음을 제공합니다:
-
2.8 TB/s의 양방향 전용 스케일업 대역폭
-
최대 6,144개의 가속기 클러스터 전체에서 예측 가능하고 고성능인 집합 연산(collective operations)
이 아키텍처는 고밀도 추론 클러스터에 대해 확장 가능한 성능을 제공하는 동시에, Azure의 글로벌 함대 전체에서 전력 사용량과 전체 소유 비용(TCO)을 절감합니다. 각 트레이(tray) 내에서 4개의 Maia 가속기는 직접 연결된 비스위칭(non-switched) 링크로 완전히 연결되어, 최적의 추론 효율성을 위해 고대역폭 통신을 로컬에 유지합니다. 동일한 통신 프로토콜이 Maia AI 전송 프로토콜을 사용하는 랙 내부 및 랙 간 네트워킹에 사용되므로, 최소한의 네트워크 홉으로 노드, 랙 및 가속기 클러스터 간의 원활한 확장이 가능합니다. 이 통합 패브릭은 프로그래밍을 단순화하고 워크로드 유연성을 향상시키며, 클라우드 규모에서 일관된 성능과 비용 효율성을 유지하면서 유휴 용량을 줄여줍니다.

클라우드 네이티브 개발 방식
마이크로소프트 실리콘 개발 프로그램의 핵심 원칙은 최종 실리콘이 나오기 전에 가능한 한 많은 엔드투엔드 시스템을 검증하는 것입니다. 정교한 사전 실리콘 환경이 초기 단계부터 Maia 200 아키텍처를 가이드했으며, LLM의 계산 및 통신 패턴을 높은 충실도로 모델링했습니다. 이러한 조기 공동 개발 환경 덕분에 첫 실리콘이 나오기 훨씬 전부터 실리콘, 네트워킹 및 시스템 소프트웨어를 하나의 통합된 개체로 최적화할 수 있었습니다. 또한 우리는 데이터센터에서 빠르고 원활하게 사용할 수 있도록 처음부터 Maia 200을 설계했으며, 백엔드 네트워크와 2세대 폐쇄 루프 액체 냉각 열교환기(Heat Exchanger Unit)를 포함한 가장 복잡한 시스템 요소들에 대한 조기 검증을 구축했습니다. Azure 제어 평면과의 기본 통합은 칩 및 랙 수준에서 보안, 텔레메트리, 진단 및 관리 기능을 제공하여 생산에 중요한 AI 워크로드의 신뢰성과 업타임을 극대화합니다. 이러한 투자의 결과로, AI 모델은 첫 패키징 부품이 도착한 지 며칠 만에 Maia 200 실리콘에서 실행되었습니다. 첫 실리콘에서 첫 데이터센터 랙 배포까지 걸린 시간은 유사한 AI 인프라 프로그램의 절반 이하로 단축되었습니다. 칩에서 소프트웨어, 데이터센터에 이르는 이러한 엔드투엔드 접근 방식은 더 높은 가동률, 더 빠른 생산 투입, 그리고 클라우드 규모에서의 달러당 및 와트당 성능의 지속적인 개선으로 직결됩니다.

Maia SDK 프리뷰 신청
대규모 AI 시대는 이제 막 시작되었으며, 인프라가 그 가능성을 정의할 것입니다. 우리의 Maia AI 가속기 프로그램은 다세대로 설계되었습니다. 글로벌 인프라에 Maia 200을 배포하는 동시에 우리는 이미 다음 세대를 설계하고 있으며, 각 세대가 지속적으로 가능성의 새로운 기준을 세우고 가장 중요한 AI 워크로드에 대해 더 나은 성능과 효율성을 제공할 것으로 기대합니다.
오늘 우리는 개발자, AI 스타트업 및 학계가 새로운 Maia 200 소프트웨어 개발 키트(SDK)를 사용하여 초기 모델 및 워크로드 최적화를 탐색하기 시작하도록 초대합니다. SDK에는 Triton 컴파일러, PyTorch 지원, NPL 저수준 프로그래밍, 그리고 코드 라이프사이클 초기 단계에서 효율성을 최적화하기 위한 Maia 시뮬레이터 및 비용 계산기가 포함되어 있습니다. 프리뷰 신청은 여기에서 하실 수 있습니다. Maia 200 사이트에서 더 많은 사진, 비디오 및 리소스를 확인하고 더 자세한 내용을 읽어보십시오.
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------