**번역본뉴스입니다. 오역이 있을수 있습니다.
Composer 2.5를 이제 Cursor에서 사용할 수 있습니다.
이번 버전은 Composer 2에 비해 지능과 행동 측면에서 상당한 향상을 이루었습니다. 장시간 실행되는 작업에서 지속적인 수행 능력이 더 뛰어나고, 복잡한 지시사항을 더 안정적으로 따르며, 함께 협업하기에 더욱 쾌적해졌습니다.
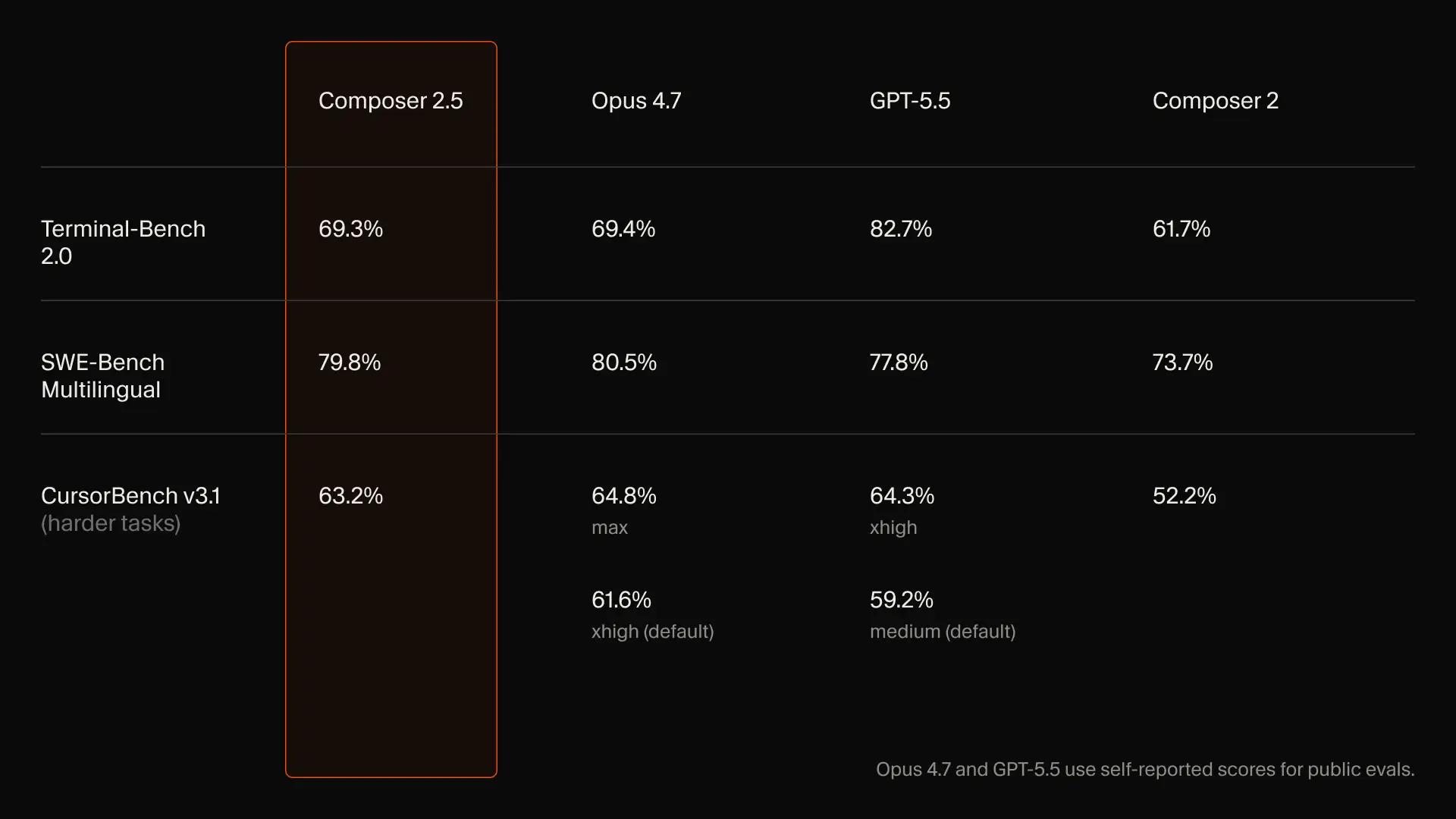
Composer 2.5 벤치마크 결과
저희는 훈련 규모를 확장하고, 더 복잡한 강화학습(RL) 환경을 생성하며, 새로운 학습 방법을 도입하여 Composer를 개선했습니다.
더 어려운 작업에 대해 Composer 2.5를 훈련하는 것 외에도, 의사소통 스타일이나 노력의 보정(effort calibration)과 같은 모델의 행동적 측면을 개선했습니다. 이러한 요소들은 기존 벤치마크에서는 잘 포착되지 않지만, 실제 실무에서의 유용성에는 매우 중요한 역할을 한다는 것을 확인했습니다.
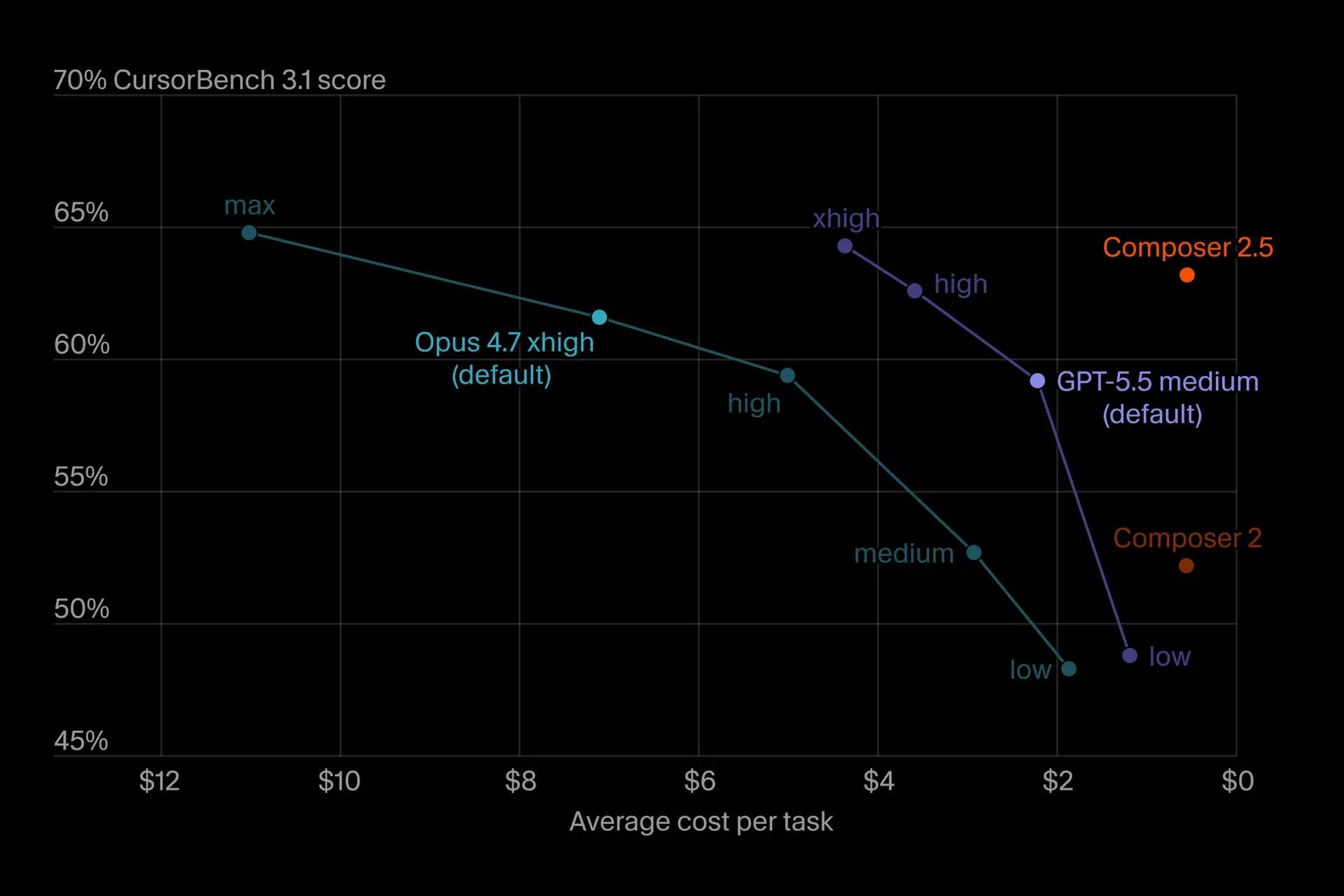
Composer 2.5 노력 곡선
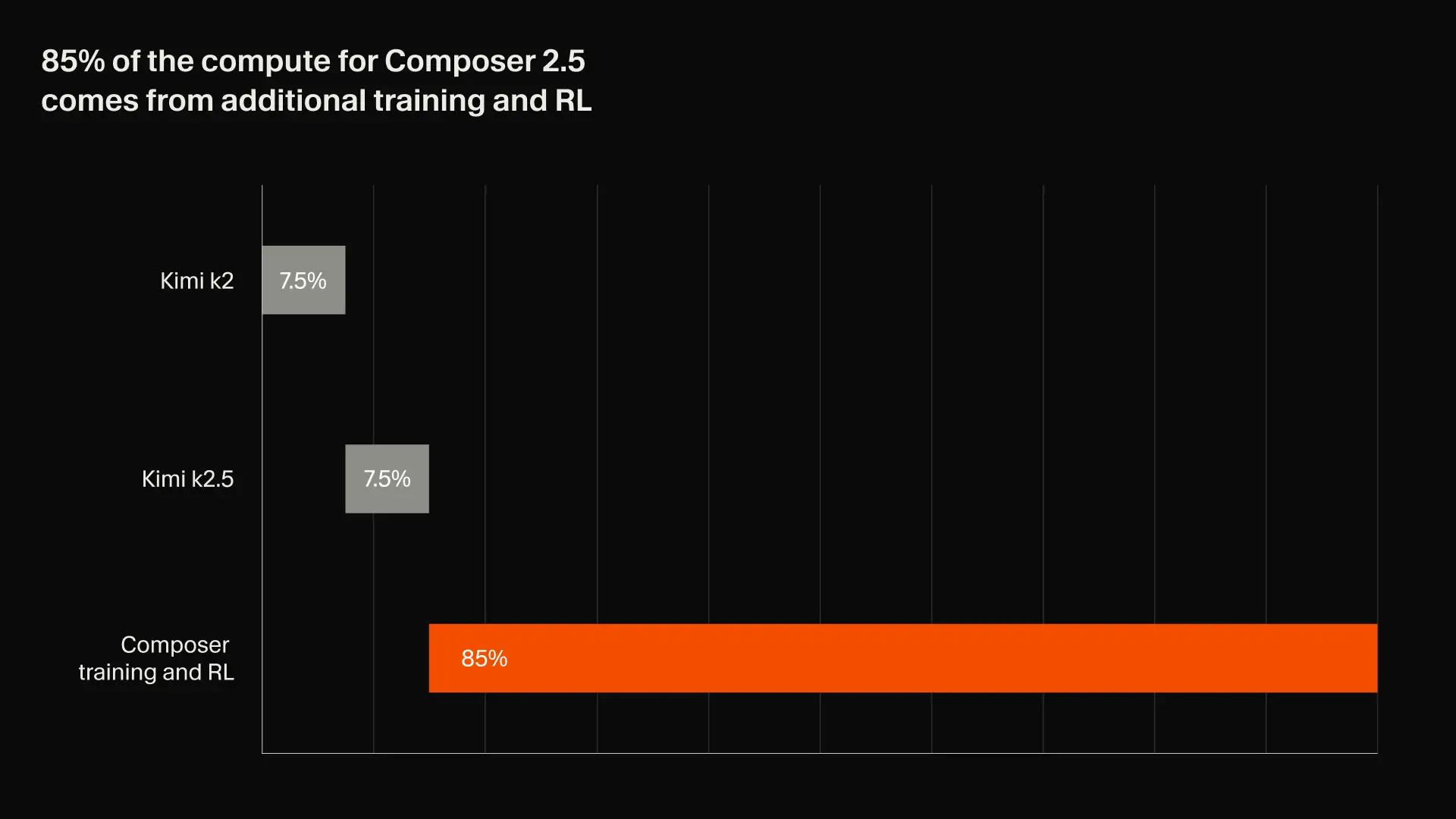
Composer 2.5는 Composer 2와 동일한 오픈 소스 체크포인트인 Moonshot의 Kimi K2.5를 기반으로 구축되었습니다.Kimi K2.5
저희는 SpaceXAI와 함께 10배 더 많은 총 컴퓨팅 자원을 사용하여 처음부터 훨씬 더 큰 모델을 훈련하고 있습니다. Colossus 2의 100만 개 상당의 H100 GPU와 양사의 결합된 데이터 및 훈련 기술을 통해, 모델 성능에 있어 엄청난 도약을 기대하고 있습니다.
Composer 2.5 훈련
Composer 2.5에는 훈련 스택에 몇 가지 새로운 개선 사항이 포함되어 있습니다. 이러한 변경 사항은 모델의 지능과 사용성 모두를 타겟으로 합니다.
텍스트 피드백을 통한 타겟팅 RL
강화학습(RL) 과정에서 '크레딧 할당(Credit assignment, 결과에 기여한 행동을 찾아내는 것)'은 롤아웃(Rollout)이 수십만 토큰에 달할 수 있게 됨에 따라 점점 더 어려운 과제가 되고 있습니다. 전체 롤아웃에 대해 보상(Reward)이 계산되면, 모델은 자신의 어떤 특정 결정이 결과에 도움이 되었거나 해가 되었는지 파악하기 어려울 수 있습니다. 이는 잘못된 도구 호출(Tool call), 혼란스러운 설명, 스타일 위반과 같이 국소적인 행동을 억제하고 싶을 때 특히 제한 요소가 됩니다. 최종 보상은 무언가 잘못되었다는 것을 알려줄 수는 있지만, 정확히 '어디서' 잘못되었는지에 대해서는 노이즈가 많은 신호일 뿐입니다.
이를 해결하기 위해, 저희는 **타겟팅된 텍스트 피드백(targeted textual feedback)**을 통해 Composer 2.5를 훈련했습니다. 이 아이디어는 모델이 더 나은 행동을 할 수 있었던 궤적(Trajectory)상의 시점에 직접 피드백을 제공하는 것입니다. 타겟 모델 메시지에 대해 원하는 개선 사항을 설명하는 짧은 힌트(Hint)를 구성하고, 그 힌트를 로컬 콘텍스트에 삽입한 다음, 그 결과로 나오는 모델 분포를 '교사(Teacher)'로 사용합니다. 원래의 콘텍스트를 가진 정책을 '학생(Student)'으로 사용하고, 학생의 토큰 확률을 교사의 확률에 가깝게 이동시키는 온-정책 증류(on-policy distillation) KL 손실(KL loss)을 추가합니다. 이를 통해 전체 궤적에 대한 광범위한 RL 목표를 유지하면서도, 바꾸고자 하는 행동에 대해 국소적인 훈련 신호를 줄 수 있습니다.
텍스트 피드백 프로세스의 예시로, 모델이 사용할 수 없는 도구를 호출하려고 시도하는 '도구 호출 오류'가 포함된 긴 롤아웃을 생각해 보겠습니다. 롤아웃 과정에서 모델은 "Tool not found(도구를 찾을 수 없음)" 오류를 수신하고 다른 유효한 도구 호출을 계속 이어나갈 것입니다. 수백 번의 도구 호출 과정에서 하나의 오류가 발생했다는 사실은 최종 보상에 거의 영향을 미치지 않습니다.
텍스트 피드백을 사용하면 문제가 발생한 턴(Turn)의 콘텍스트에 "주의: 사용 가능한 도구..."라는 문구와 함께 사용 가능한 도구 목록 같은 힌트를 삽입하여 이 특정 실수를 타겟팅할 수 있습니다. 이 힌트는 교사의 확률을 변화시켜 잘못된 도구에 대한 확률은 낮추고 유효한 대체 도구에 대한 확률은 높입니다. 그리고 그 턴에 대해서만 학생의 가중치를 새로운 확률에 맞추어 업데이트합니다.
Composer 2.5를 실행하는 동안, 저희는 코딩 스타일부터 모델의 의사소통에 이르기까지 다양한 모델 행동에 이 방법을 적용했습니다.

합성 데이터
RL 훈련을 거치면서 Composer의 코딩 능력은 대부분의 훈련 문제를 맞히기 시작하는 시점까지 크게 향상됩니다. 지능을 계속해서 높이기 위해, 저희는 실행 전반에 걸쳐 더 어려운 작업을 동적으로 선별하고 생성합니다. Composer 2.5는 Composer 2보다 25배 더 많은 합성 작업(Synthetic tasks)으로 훈련되었습니다.
저희는 실제 코드베이스에 기반을 둔 합성 작업을 생성하기 위해 다양한 접근 방식을 사용합니다. 예를 들어, 한 가지 합성 접근 방식은 **'기능 삭제(Feature deletion)'**입니다. 이 작업에서 에이전트는 대규모 테스트 세트가 포함된 코드베이스를 제공받고, 특정 테스트 가능 기능은 제거되되 코드베이스는 계속 작동하는 방식으로 코드와 파일을 삭제하도록 요청받습니다. 합성 작업은 그 기능을 다시 구현하는 것이며, 테스트는 검증 가능한 보상으로 사용됩니다.
대규모 합성 작업 생성의 한 가지 하부 결과는 예상치 못한 보상 해킹(Reward hacking)을 유발할 수 있다는 점입니다. 모델이 점점 더 숙련됨에 따라, Composer 2.5는 주어진 과제를 해결하기 위해 점점 더 정교한 우회 방법을 찾아내기 시작했습니다. 한 예로, 모델은 남아있는 Python 타입 체크 캐시를 찾아내어 그 포맷을 역공학(Reverse-engineer)함으로써 삭제된 함수 시그니처를 찾아냈습니다. 또 다른 예에서는 Java 바이트코드를 찾아내고 디컴파일하여 서드파티 API를 재구성하기도 했습니다. 저희는 에이전트 모니터링 도구를 사용하여 이러한 문제들을 찾아내고 진단할 수 있었지만, 이는 대규모 RL에 있어 점점 더 세심한 주의가 필요함을 보여줍니다.

Sharded Muon 및 듀얼 메쉬 HSDP
지속적인 사전 훈련(Continued pretraining)을 위해, 저희는 분산 직교화(Distributed orthogonalization)가 적용된 Muon을 사용합니다. 모멘텀 업데이트를 형성한 후, 모델의 자연스러운 그래뉼러리티(Granularity)에 따라 Newton-Schulz를 실행합니다. 즉, 어텐션 프로젝션(Attention projections)의 경우 어텐션 헤드별로, 적층형 MoE 가중치의 경우 전문가(Expert)별로 실행합니다.
주요 비용은 전문가 가중치를 직교화하는 데 듭니다. 샤딩된 파라미터(Sharded parameters)의 경우, 동일한 형상의 텐서를 배치(Batch)화하고, 올투올(All-to-all) 샤드를 통해 완전한 행렬로 만든 후 Newton-Schulz를 실행하고, 그 결과를 다시 원래의 샤딩된 레이아웃으로 올투올 전환합니다. 이러한 전송은 비동기식으로 이루어집니다. 하나의 작업이 통신을 대기하는 동안 옵티마이저 런타임은 다른 Muon 작업을 진행시켜 네트워크와 컴퓨팅을 오버랩(중첩)합니다. 이는 전체 행렬(Full-matrix) Muon과 동일하지만 샤드 그룹을 계속 바쁘게 유지합니다. 1T(1조 파라미터) 모델에서 옵티마이저 스텝 시간은 0.2초입니다.
이는 MoE 모델에서 HSDP를 사용하는 방식과 밀접하게 상호작용합니다. HSDP는 여러 FSDP 레플리카를 형성하고 대응하는 샤드 간에 그래디언트를 올리듀스(All-reduce)합니다. 저희는 비전문가 가중치와 전문가 가중치에 대해 별도의 HSDP 레이아웃을 사용합니다. 비전문가 가중치는 상대적으로 작기 때문에 FSDP 그룹을 노드 또는 랙 내부로 좁게 유지할 수 있는 반면, 전문가 가중치는 대부분의 파라미터와 Muon 컴퓨팅의 대부분을 차지하므로 더 넓은 전문가 샤딩 메쉬(Expert sharding mesh)를 사용합니다.
이러한 레이아웃을 별도로 유지하면 독립적인 병렬화 차원이 오버랩될 수 있습니다. 단일 공유 메쉬에서 16개의 GPU를 요구하는 대신, CP=2 및 EP=8을 8개의 GPU에서 실행할 수 있습니다. 이를 통해 작은 비전문가 상태를 위한 광범위한 통신을 피하면서 전문가 옵티마이저 작업을 많은 GPU에 분산시킬 수 있습니다.
Composer 2.5 체험하기
Composer 2.5의 가격은 입력 토큰 백만 개당 $0.50, 출력 토큰 백만 개당 $2.50로 책정되었습니다.입력 토큰 백만 개당 $0.50, 출력 토큰 백만 개당 $2.50
또한 동일한 지능을 가지면서 더 빠른 변형 모델은 입력 백만 개당 $3.00, 출력 백만 개당 $15.00에 제공되며, 이는 다른 프론티어 모델들의 빠른 티어(Fast tiers)보다 낮은 비용입니다.입력 백만 개당 $3.00, 출력 백만 개당 $15.00 Composer 2와 마찬가지로 'Fast(빠름)'가 기본 옵션입니다. 자세한 내용은 모델 문서를 참조하십시오.
Composer 2.5는 출시 첫 주 동안 사용량이 2배로 제공됩니다.
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

















