**번역본뉴스입니다. 오역이 있을수 있습니다.
엔비디아가 자사 역대 가장 강력한 모델이자 네모트론 3 제품군의 대미를 장식할 최종 완결판인 '네모트론 3 울트라(Nemotron 3 Ultra)'를 선보였습니다. 이 모델은 총 5,500억 개(550B)의 매개변수(파라미터)와 550억 개(55B)의 활성 매개변수를 갖추고 있습니다.
핵심 기능
-
하이브리드 맘바-어텐션(Mamba-Attention) 아키텍처: 전문가 믹스(MoE) 구조와 하이브리드 아키텍처를 채택했습니다.
-
레이턴트MoE(LatentMoE): 정확도를 한층 더 개선하기 위해 레이턴트MoE 기술을 활용합니다.
-
MTP(Multi-Token Prediction) 레이어: 네이티브 추측 디코딩(Speculative decoding)을 통해 더 빠른 추론 속도를 구현합니다.
-
추론 시간 추론 예산 제어(Inference time reasoning budget control): 추론 시 연산 리소스 및 예산 제어 기능을 지원합니다.
-
NVFP4 사전 훈련: 엔비디아의 초저정밀도 데이터 포맷인 NVFP4 환경에서 사전 훈련되었습니다.
-
강화된 사후 훈련: 모델의 정확도를 끌어올리기 위해 지도 미세 조정(SFT), 강화 학습(RL), 그리고 멀티 티처 온포리시 증류(MOPD)가 포함된 정교한 파이프라인을 거쳤습니다.
주요 하이라이트
-
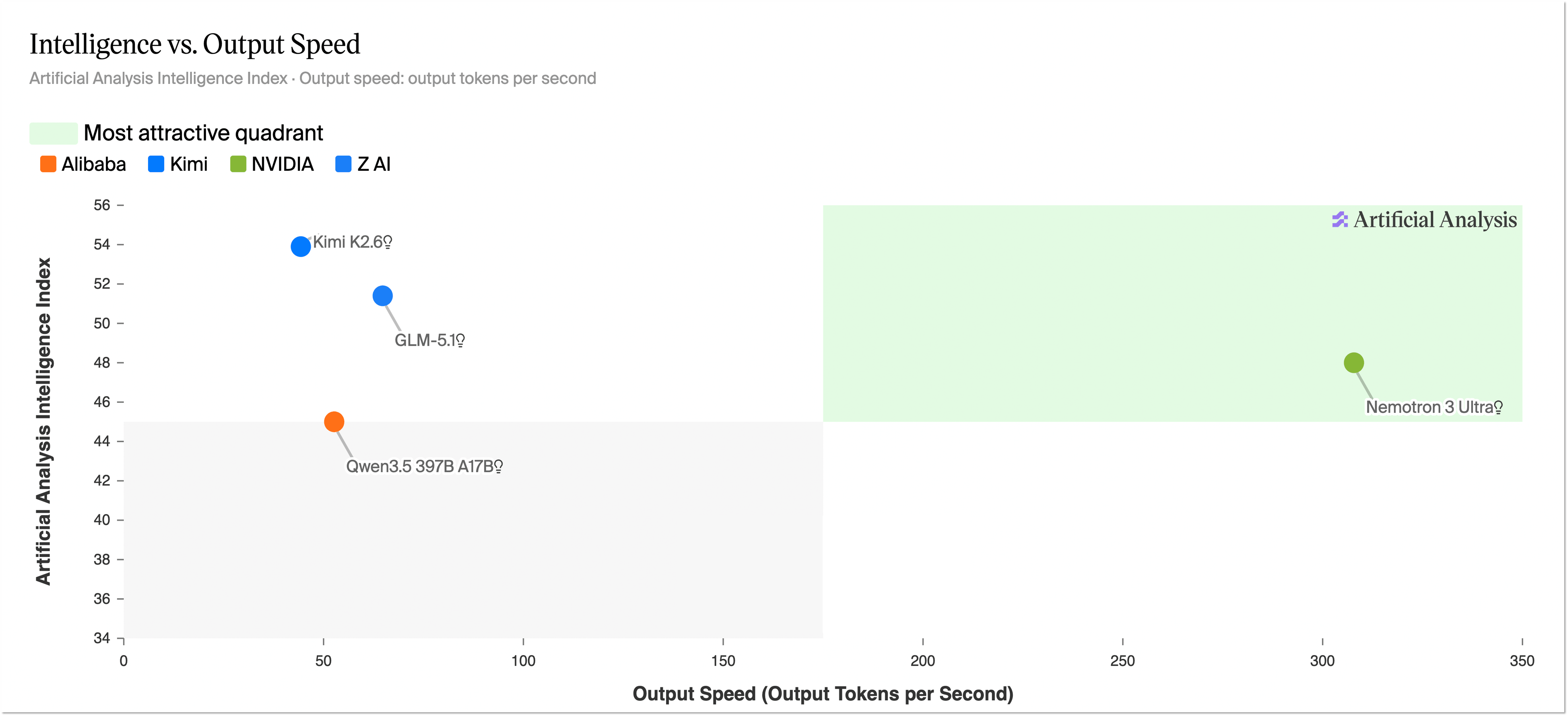
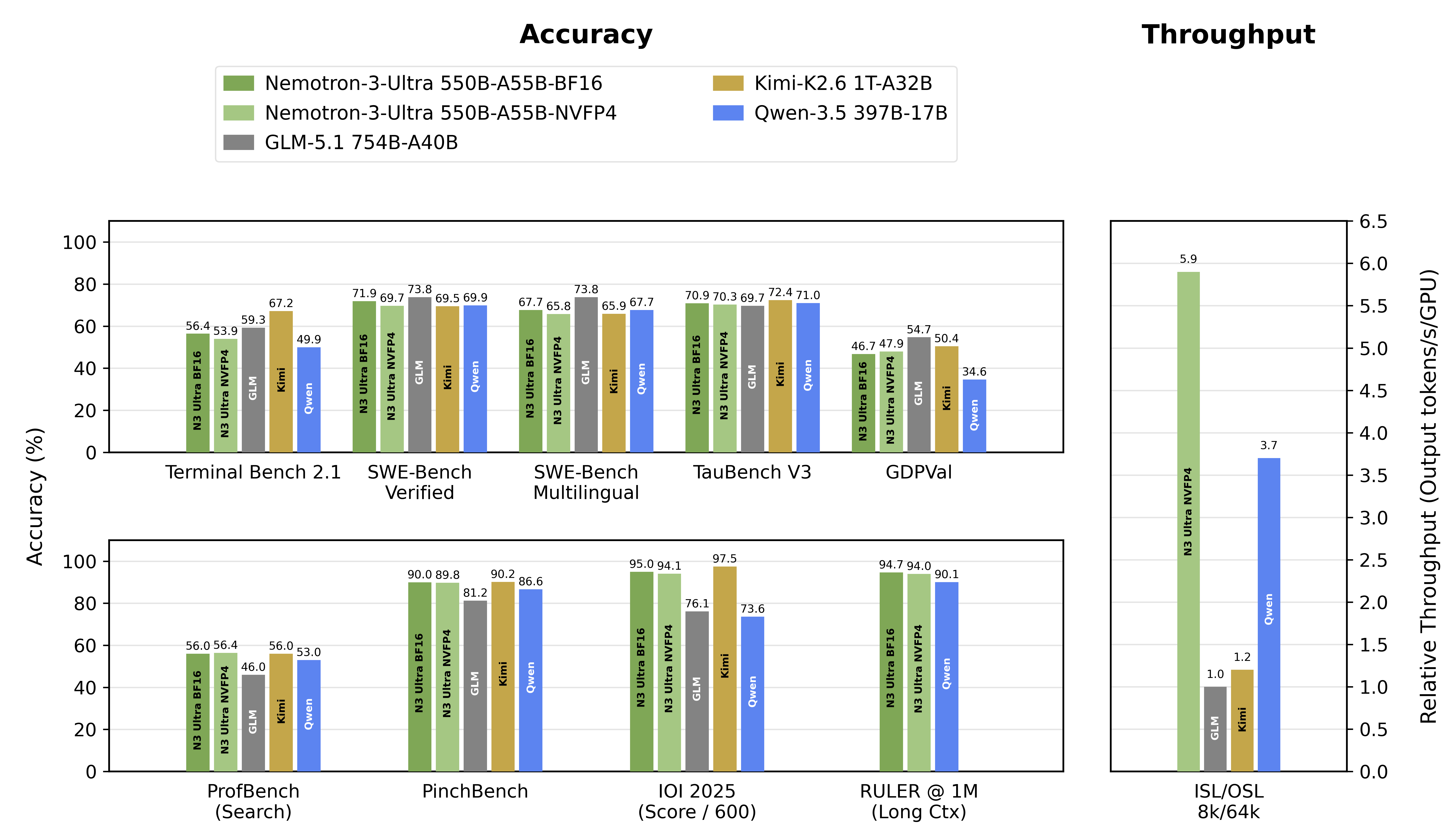
압도적인 추론 처리량(Throughput): 8k 토큰 입력 / 64k 토큰 출력 설정에서 네모트론 3 울트라는 경쟁 모델인 GLM-5.1-754B-A40B 대비 5.9배, Kimi-K2.6-1T-A32B 대비 4.8배, Qwen-3.5-397B-17B 대비 1.6배 더 높은 추론 처리량을 달성했습니다.
-
최정상급 정확도: 다양한 벤치마크 전반에서 기존 최고 수준(SOTA)의 다른 오픈소스 LLM들과 대등한 수준의 정확도를 보여줍니다.
-
100만(1M) 토큰 컨텍스트 지원: 최대 1M 토큰의 컨텍스트 길이를 지원하며, 1M 컨텍스트 길이 기준의 RULER 벤치마크에서 기존 SOTA 오픈소스 LLM들을 능가하는 성적을 거두었습니다.
오픈소스 공개 안내
엔비디아는 사전 훈련(Pre-trained), 사후 훈련(Post-trained), 양자화(Quantized) 체크포인트와 함께 훈련에 사용된 데이터 세트를 모두 전면 공개합니다.
체크포인트(Checkpoints):
-
Nemotron 3 Ultra 550B-A55B NVFP4: 사후 훈련 및 NVFP4 양자화가 완료된 모델 -
Nemotron 3 Ultra 550B-A55B BF16: 사후 훈련이 완료된 BF16 모델 -
Nemotron 3 Ultra 550B-A55B Base BF16: 베이스(기초) 모델 -
Nemotron 3 Ultra 550B-A55B GenRM: 인간 피드백 기반 강화학습(RLHF)에 사용된 생성형 보상 모델(GenRM)
공개 데이터(Data):
-
Nemotron-Pretraining-Code-v3: 2025년 9월 30일까지 깃허브(GitHub)에서 수집한 1,730억(173B) 토큰 규모의 신규 코드 데이터 -
Nemotron-Pretraining-Legal-v1: LLM의 법률 분야 역량 강화를 위해 고안된 합성 데이터 세트 모음 -
Nemotron-Pretraining-Specialized-v1.2: 사실적 회상(Factual recall), 도덕적 시나리오, 다양한 생성형 및 객관식 질문에 대한 LLM 능력을 개선하기 위한 합성 데이터 세트 모음 -
Nemotron-Posttraining-v3: SFT 및 RL 과정에서 에이전트 능력, 추론 능력 및 전반적인 모델 성능을 향상시키기 위한 사후 훈련 데이터 세트 모음
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------