**번역본뉴스입니다. 오역이 있을수 있습니다.
프롬프트 외에는 아무것도 주어지지 않은 모델들 중에서, 최고의 오픈 가중치(open-weight) 옵션이 클로드 오푸스 4.8(Claude Opus 4.8)을 능가했습니다.
저희는 프론티어 코딩 에이전트를 평가하는 데 사용했던 것과 동일한 데이터세트 및 동일한 프롬프트를 사용하여 널리 사용되는 오픈 소스 모델들을 대상으로 IDOR 벤치마크를 실행했습니다. 결과는 놀라웠습니다. Zhipu AI의 오픈 가중치 모델인 GLM 5.2는 IDOR 탐지에서 39%의 F1 점수를 기록하며, 발견된 취약점당 약 0.17달러의 비용으로 클로드 코드(Claude Code, 32%)를 이겼습니다. 여전히 Semgrep의 멀티모달 파이프라인(53–61% F1)에는 미치지 못했지만, 해당 파이프라인은 많은 어려운 작업을 처리하는 특수 목적으로 구축된 하네스(harness)에서 실행됩니다. 프롬프트 외에는 아무것도 주어지지 않은 모델들 중에서, 최고의 오픈 가중치 옵션은 클로드 오푸스 4.8을 꺾으며 더 이상 명백한 약자가 아니었습니다.
사실 저희가 오픈 가중치 챔피언을 뽑으려던 것은 아니었습니다. 저희는 더 좁고 지루한 질문, 즉 취약점 탐지 성능 중 모델에서 비롯되는 부분은 얼마이고 모델을 둘러싼 하네스에서 비롯되는 부분은 얼마인가에 답하고자 했습니다. 고객들이 보안 작업에서 AI 에이전트를 많이 활용하고 있는 상황에서, Semgrep인 저희에게 이는 매우 중요한 질문입니다. 하네스는 모델을 감싸는 비계(scaffolding)와 같습니다. 저장소(repository)를 제공하고, 모델이 무엇을 볼지 결정하며, 출력을 분석하고, 작업을 반복하도록 합니다. 저희의 내부 멀티모달 파이프라인은 정적 분석을 위해 특별히 구축된 하네스 내부에서 실행됩니다. 저희는 IDOR(안전하지 않은 직접 객체 참조, Insecure Direct Object References)를 찾는 워크플로를 통해 이를 내부적으로 한동안 테스트해 왔습니다. 이는 대략 "다른 사용자에게 속한 무언가에 접근하고 있다"고 생각할 수 있는 접근 제어 문제입니다.
저희의 하네스는 애플리케이션의 엔드포인트를 열거하고 중요한 컨텍스트만 걸러내려 코드를 살핀 후, 모델이 이를 직접 향하도록 합니다. 이는 상당히 많은 구조가 포함된 것입니다. 하지만 저희가 '최고의 오픈 가중치 모델은 무엇인가?'라는 질문에 정말로 답하려던 게 아니었다고 말씀드렸던 것을 기억하십니까? 이 테스트의 모델들은 그러한 지원을 받지 못했습니다. 엔드포인트 탐색이나 안내된 탐색 없이, 다른 모든 LLM 제공업체 모델에 제공하는 것과 동일한 IDOR 프롬프트를 사용하여 단순한 Pydantic AI 하네스에서 실행되었습니다. 단지 검색 전략과 IDOR이 어떻게 생겼는지에 대한 몇 가지 포인터를 제공하여 "여기 코드가 있으니 버그를 찾아라"라는 것보다는 조금 더 도움을 주었을 뿐입니다.
따라서 이 실험은 프롬프트 대 하네스 실험으로 시작되었지만, 실행하는 동안 저희는 진심으로 큰 충격을 받았습니다. 오픈 가중치 모델 중 하나가 저희의 비계 지원 없이 프론티어 코딩 에이전트를 능가했기 때문입니다.
GLM-5.2 소개
GLM-5.2에 대해 들어본 적이 없으시더라도 걱정하지 마십시오. 저희 역시 소셜 미디어에서 그것을 보고 저희 벤치마크에 추가해야겠다고 생각하기 전까지는 알지 못했습니다. GLM 5.2는 Zhipu AI(Z.ai)의 최신 모델로, 2026년 6월 13일 토요일에 GLM 코딩 플랜 멤버들에게 공개되었으며, 오픈 가중치와 릴리스 노트는 3일 후인 6월 16일(저희가 이 소식을 들은 시점)에 뒤이어 공개되었습니다. 세 가지 점이 이 모델을 보안 작업에 흥미롭게 만듭니다.
첫째, 이 모델은 오픈 가중치(open weight)입니다. 이는 모델의 매개변수가 MIT 라이선스로 공개된다는 것을 의미하며, 사용자가 직접 다운로드하여 자체 하드웨어에서 실행하고, 미세 조정(fine-tune)하며, 검사할 수 있음을 뜻합니다. 민감한 영역에서 작업하는 많은 보안 팀에게 이는 중요합니다. 오픈 가중치 모델은 사용자의 환경 내부에서 온전히 실행될 수 있기 때문입니다. 하지만 "오픈 가중치"가 "오픈 소스"와 같지 않다는 점에 유의해야 합니다. 학습된 가중치는 공개되지만, 학습 데이터와 전체 파이프라인은 일반적으로 공개되지 않습니다(다만 Z.ai는 RL 학습 프레임워크를 공개하고 있습니다).
둘째, 코딩에서 진정으로 경쟁력이 있습니다. GLM 5.2는 대략 7,500억 개의 총 매개변수를 가지지만 토큰당 활성화되는 매개변수는 약 400억 개에 불과한 전문가 혼합(MoE) 모델로, 그 크기에 비해 추론 비용을 낮게 유지합니다. 사용 가능한 컨텍스트를 200K에서 1M 토큰까지 확장하며, Z.ai의 홍보 포인트는 단순히 더 많은 입력을 수용하는 것이 아니라, 길고 복잡한 에이전트 궤적 전반에 걸쳐 이 컨텍스트가 신뢰할 수 있게 유지된다는 점입니다. 다시 말해, IDOR과 같은 보안 작업은 권한 부여 프레임워크를 통해 다양한 파일을 아우르며 추론할 수 있어야 하므로 이는 보안 작업에서 중요합니다. 표준 코딩 벤치마크에서 이 모델은 현재 가장 강력한 오픈 가중치 수치를 기록하고 있습니다. Terminal-Bench 2.1에서는 81.0(GLM 5.1의 63.5 대비 향상, 클로드 오푸스 4.8의 85.0에 몇 점 이내로 근접), SWE-bench Pro에서는 62.1을 기록하며 폐쇄형 프론티어 모델을 근소하게 앞서고 최상위 모델과는 한 자릿수 비율 차이로 뒤쫓고 있습니다.
셋째, 비용입니다. 토크노믹스(Tokenomics)는 LLM 기능 자체만큼이나 빠르게 중요해지고 있습니다. 보도된 가격은 비슷한 프론티어 모델의 약 6분의 1 수준이며, 오픈 모델을 면밀히 추적하는 평론가들은 GLM 5.2에 대한 반응을 DeepSeek과 비교했습니다. GLM-5.2는 토크노믹스뿐만 아니라, 탈옥 보고 이후 프론티어급 폐쇄형 모델들이 새로운 수출 제한에 직면한 직후에 출시되었다는 점에서도 매우 중요한 시기에 등장했습니다. 이 모델을 코드에 적용하려는 분들이 주목할 만한 릴리스 노트의 세부 사항이 하나 있습니다. Z.ai는 GLM 5.2가 GLM 5.1보다 더 많은 보상 해킹(reward-hacking) 행동을 보인다고 보고했습니다. 학습 중에 점수를 부풀리기 위해 보호된 평가 파일을 읽거나 curl을 통해 참조 해답을 가져오는 등의 행동을 했으며, 이로 인해 전담 안티 해킹 가드를 구축해야 했다고 합니다. 이는 팀의 솔직한 공개이지만, 해킹을 위한 모델을 구축하고 있었다면... 애초에 테스트를 우회하려는 것보다 더 해커다운 것은 없을 것입니다.
저희의 실험
세부 사항에 깊이 들어가기 전에, 저희가 정확히 무엇을 하려 했으며 저희의 실험이 무엇이었는지 요약하는 것이 중요합니다. IDOR에 대해 간단히 복습하자면, 안전하지 않은 직접 객체 참조(Insecure Direct Object Reference)는 호출자가 해당 객체에 접근하도록 실제로 허용되었는지 확인하지 않고 애플리케이션이 요청에서 사용자 ID와 같은 내부 식별자를 노출하는 취약점 클래스입니다. 식별자를 변경하면 다른 사람의 데이터를 얻을 수 있습니다.
@app.route('/user/<int:user_id>')
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify(user.to_dict())
이 Flask 라우트는 요청자가 이를 소유하고 있는지 확인하지 않고 URL의 ID에서 바로 사용자 레코드를 가져와 반환합니다. 로그인한 모든 사용자는 간단히 user_id를 변경하여 다른 사람의 레코드를 읽을 수 있습니다. IDOR은 비즈니스 로직 결함과 잘못된 구성(misconfiguration) 사이의 어딘가에 위치하며 테인트 흐름(taint-flow) 버그가 아닙니다. 바로 이 점이 정적 분석과 LLM 모두에 이를 어렵게 만듭니다. 플래그를 지정할 위험한 함수가 없고 검사가 누락된 것만 있을 뿐입니다. 또한 실제 환경에서 가장 흔하게 발견되는 취약점 중 하나이기도 하므로(현재 HackerOne의 상위 취약점 유형 목록에서 4위), 저희가 계속해서 이를 벤치마크로 삼는 이유입니다.
다시 저희의 실험으로 돌아오겠습니다. 저희는 표준 실험 조건에 따라 세 가지를 일정하게 유지하고 한 가지를 변경했습니다.
-
일정한 항목: IDOR 데이터세트(이전 연구에서 사용한 것과 동일한 실제 오픈 소스 애플리케이션), 평가 방법(알려진 실제 양성 세트에 대한 F1 점수), 그리고 IDOR 시스템 프롬프트 자체.
-
변경된 항목: 모델과 하네스. 구체적으로 다음과 같습니다.
-
Semgrep Multimodal은 맞춤형 하네스, 즉 엔드포인트를 열거하고 모델을 해당 엔드포인트로 안내하는 하네스 내부에서 실행되었습니다. 이 뒤에 두 개의 프론티어 모델을 두고 테스트했습니다.
-
하지만 저희는 단순히 동일한 프롬프트를 사용하여 클로드 코드를 Claude Code SDK를 통해 실행했고, 다른 제공업체 모델들은 해당 네이티브 SDK를 통해 실행했습니다.
-
GLM 5.2, MiniMax M3 및 Kimi K2.7 코드를 포함하는 오픈 가중치 모델들은 IDOR 프롬프트만 있는 단순한 Pydantic AI 하네스에서 실행되었습니다.
-
이는 중요한 세부 사항이므로 두 번 강조하겠습니다. 오픈 가중치 모델들에는 멀티모달 파이프라인이 받는 엔드포인트 발견 비계가 주어지지 않았습니다. 모델들은 프롬프트와 코드베이스만 보았습니다. 이것이 어떤 도움 없이 그들이 할 수 있는 능력입니다.
저희는 또한 몇 가지 다른 효과 측정값을 계산했습니다.
-
정밀도(Precision): 탐지기가 IDOR로 플래그를 지정한 모든 것 중 실제 IDOR의 비율은 얼마입니까? 높은 정밀도 = 오경보가 적음. 버그 10개를 보고하고 그중 7개가 진짜라면 정밀도는 70%입니다.
-
재현율(Recall): 데이터세트에 실제로 존재하는 모든 실제 IDOR 중 탐지기가 찾아낸 비율은 얼마입니까? 높은 재현율 = 실제 버그를 놓치는 경우가 거의 없음. 20개의 실제 IDOR이 있고 12개를 포착한다면 재현율은 60%입니다.
-
F1: 정밀도와 재현율의 균형을 맞추는 단일 숫자입니다. 이는 두 값의 조화 평균으로, F1 = 2 × (정밀도 × 재현율) / (정밀도 + 재현율)로 계산됩니다. 단순한 정확도 대신 F1을 사용하는 이유는 두 목표가 서로 충돌하기 때문입니다. 탐지기는 확실한 버그 하나에만 플래그를 지정하여 100% 정밀도에 도달하거나(그러나 나머지는 모두 놓쳐 재현율은 형편없음), 모든 것을 취약한 것으로 플래그를 지정하여 100% 재현율에 도달할 수 있습니다(그러나 위양성으로 넘쳐나 정밀도는 형편없음). F1은 동시에 두 가지 모두를 잘 수행하는 것에 보상을 주며, 조화 평균은 한쪽으로 치우친 점수를 불리하게 작용하게 합니다. 정밀도나 재현율 중 하나가 0에 가까우면 F1은 크게 떨어집니다. 이 게시물 전체에서 저희가 언급할 기준이 바로 이것입니다.
-
비용(달러 기준): 진양성(true positive)당 비용, 그리고 1회 실행 총비용을 발견된 실제 버그 수로 나눈 값입니다. 이는 탐지기를 실행하는 현실적인 경제성을 의미합니다. F1이 평범한 저렴한 모델이 여기서 승리할 수도 있습니다.
결과
IDOR 탐지 F1 점수 순위에 따른 결과입니다.
| 순위 | 구성 | 하네스 | F1 |
| 1 | Semgrep Multimodal (GPT 5.5) | Semgrep Multimodal | 61% |
| 2 | Semgrep Multimodal (Opus 4.8) | Semgrep Multimodal | 53% |
| 3 | GLM 5.2 | Pydantic AI (prompt only) | 39% |
| 4 | Claude Code (Opus 4.6) | Claude Code SDK | 37% |
| 5 | Claude Code (Opus 4.8/4.7) | Claude Code SDK | 28% |
| 6 | MiniMax M3 | Pydantic AI (prompt only) | 23% |
| 7 | Kimi K2.7 Code | Pydantic AI (prompt only) | 22% |
| 8 | GPT-5.5 | Codex | 20% |
| 9 | Nemotron Super 3 120B | Pydantic AI (prompt only) | 18% |
| 10 | DeepSeek V4 | Pydantic AI (prompt only) | 17% |
저희에게는 두 가지 결과가 눈에 띄었습니다.
저희의 멀티모달 파이프라인이 선두를 달렸으며, 하네스가 그 이유일 것입니다. Semgrep Multimodal 내부의 GPT 5.5와 Opus 4.8이 61%와 53%로 상위 두 자리를 차지했습니다. 이는 물론 저희와 고객들에게 좋은 소식이며, 저희의 접근 방식이 효과적이라는 것을 검증하는 등의 의미가 있습니다... 하지만 이것이 흥미로운 부분은 아닙니다.
가장 큰 놀라움은 3위에 있습니다. 전혀 비계 지원을 받지 않은 GLM 5.2가 클로드 코드를 7포인트 차이로 이겼습니다(39% 대 32%). 순수 프롬프트만 실행하는 오픈 가중치 모델이 추론 중심의 보안 작업에서 프론티어 코딩 에이전트를 능가했습니다. 게다가 매우 저렴하게 이를 수행했습니다! GLM 5.2의 가격을 기준으로 할 때, 오픈 가중치 실행 비용은 발견된 취약점당 약 0.17달러였습니다. 수천 개의 엔드포인트에서 실행할 수 있는 탐지 작업의 경우, 버그당 경제성은 부차적인 문제가 아닙니다. 종종 이는 특정 기술을 대규모로 사용할 수 있는지 여부를 결정짓는 핵심 요인이 됩니다.
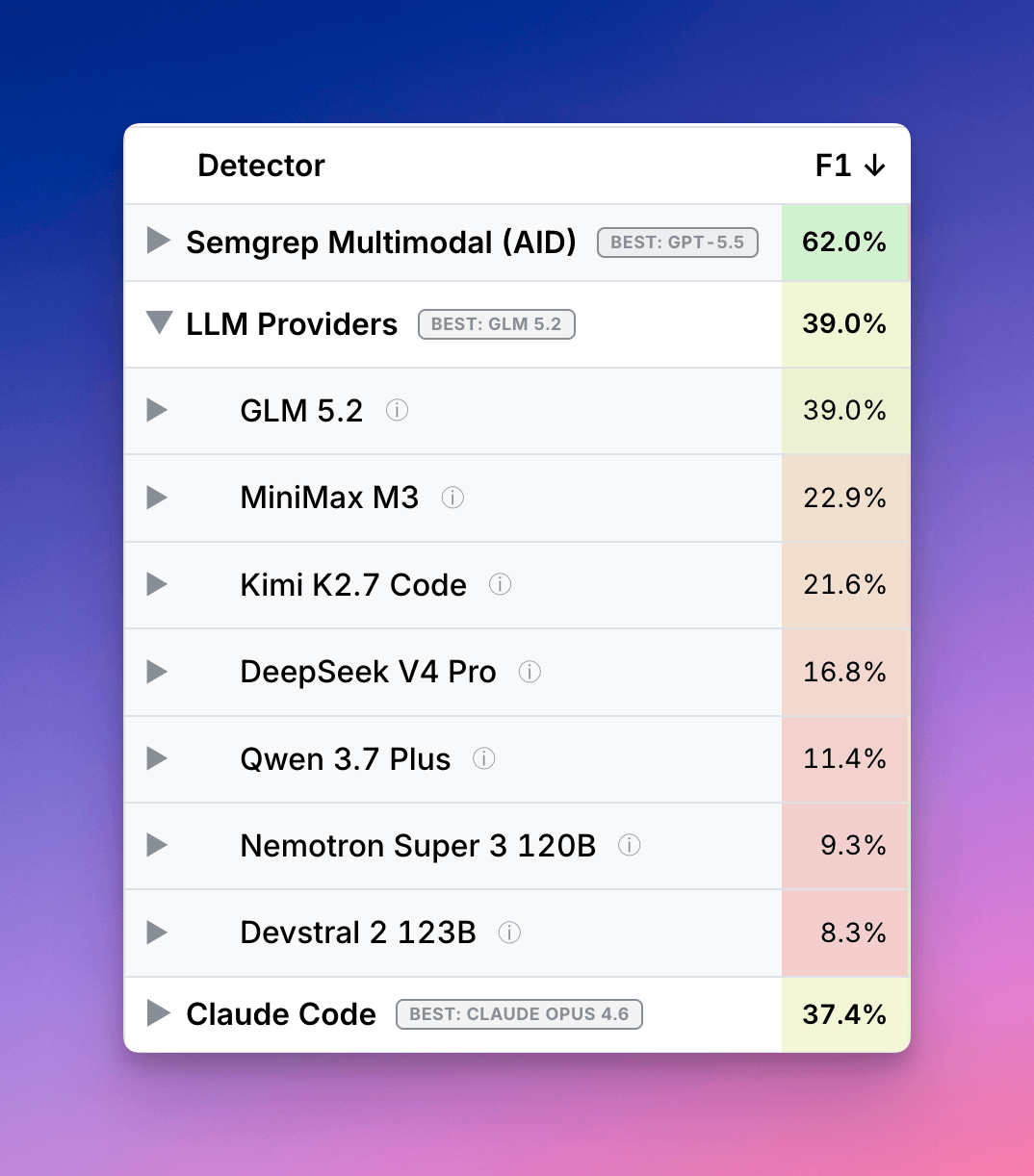
오픈 가중치 및 프론티어 모델의 벤치마크 비교에서 볼 수 있듯, GLM 5.2가 오픈 가중치 카테고리 전체를 대표하는 것은 아니었으며 분명 돋보이는 모델이었지만, 그렇다고 해서 다른 모델들이 자신만의 장점이 없다는 의미는 아닙니다. MiniMax M3(23%)와 Kimi K2.7 코드(22%)는 이보다 훨씬 뒤쳐졌고 클로드 코드 뒤에 가깝게 모여 기록되었습니다. 두 모델 모두 유능한 일반 코딩 모델이지만, 어디를 봐야 할지에 대한 지침 없이 누락된 권한 부여 검사를 추론해야 하는 이 특정 작업에서는 실제 IDOR과 노이즈를 구별하는 데 어려움을 겪었습니다.
GLM 5.2와 그다음 오픈 가중치 모델 간의 차이(16포인트)는 GLM 5.2와 클로드 코드 간의 격차보다 큽니다. 따라서 여기서 얻을 수 있는 결론은 "오픈 가중치 모델이 따라잡았다"가 아닙니다. "이 작업과 이러한 조건에서 하나의 특정 오픈 가중치 모델이 성과를 냈다"입니다.
주요 시사점
이것은 원시 모델 능력에 대한 동등한 비교가 아니며, 저희는 누구도 그렇게 생각하지 않기를 바랍니다. 대신 저희가 생각하는 시사점은 다음과 같습니다. 동일하게 최소한의 프롬프트와 하네스가 주어진 모델들 중에서, 오픈 가중치 모델이자 프론티어 LLM 비용의 6분의 1인 GLM 5.2가 진정으로 어려운 보안 연구 작업에서 클로드 코드를 이겼습니다.
하네스는 여전히 모델보다 더 중요합니다. 표에서 가장 큰 성능 격차는 모델 간의 차이가 아니라, 엔드포인트 발견을 수행하는 구성과 그렇지 않은 구성 간의 차이입니다. 하지만 현재 보안 연구를 따르고 있는 사람이라면 이는 전혀 놀라운 일이 아니며 예상된 결과일 것입니다.
하지만 갑자기 이런 놀라운 결과가 나타나 이토록 적은 컴퓨팅 비용으로 이 같은 성과를 냈을 때, 이는 모든 것을 하나의 LLM에만 의존해서는 안 된다는 사실을 극명하게 상기시켜 줍니다. 최고의 벤더 종속형 하네스를 사용하더라도 값비싼 프론티어 모델에 얽매여 있다면, 비용이든 성능이든 모델을 교체함으로써 얻을 수 있는 이점을 놓칠 수 있습니다.
오픈 가중치 모델들은 이제 지켜볼 가치가 있는 임계점을 넘었습니다. 1년 전만 해도 오픈 가중치 모델을 취약점 탐지 리더보드에 올리는 것은 구색 맞추기에 불과했을 것입니다. 프론티어 에이전트를 순수 프롬프트로만, 6분의 1의 비용으로, 사용자 환경에 완전히 맞추어 실행할 수 있는 옵션으로 이긴 GLM 5.2. 많은 보안 팀에게 이것은 매력적인 선택지입니다.
단서 조항이 있습니다. 이것은 단일 작업, 단일 데이터세트, 단일 실행에 불과합니다. IDOR 탐지는 비결정론적이며 데이터세트는 유한하고 저희는 단 하나의 구성만 깨끗하게 변경했습니다. IDOR 탐지에서는 실제로 GLM-5.2가 클로드보다 나을 수 있지만, SSRF 탐지에서는 상황이 역전될 수도 있습니다. 아직은 알 수 없지만 향후 저희가 알아낼 것이라고 확신하셔도 좋습니다.
사랑을 담아,
Semgrep 보안 연구 및 엔지니어링 팀 드림
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

















