

**번역본뉴스입니다. 오역이 있을수 있습니다.
주요 포인트
우리는 Llama 4 시리즈의 첫 번째 모델을 공개합니다. 이 모델들은 사람들이 더 개인화된 멀티모달 경험을 구축하는 데 도움이 될 것입니다.
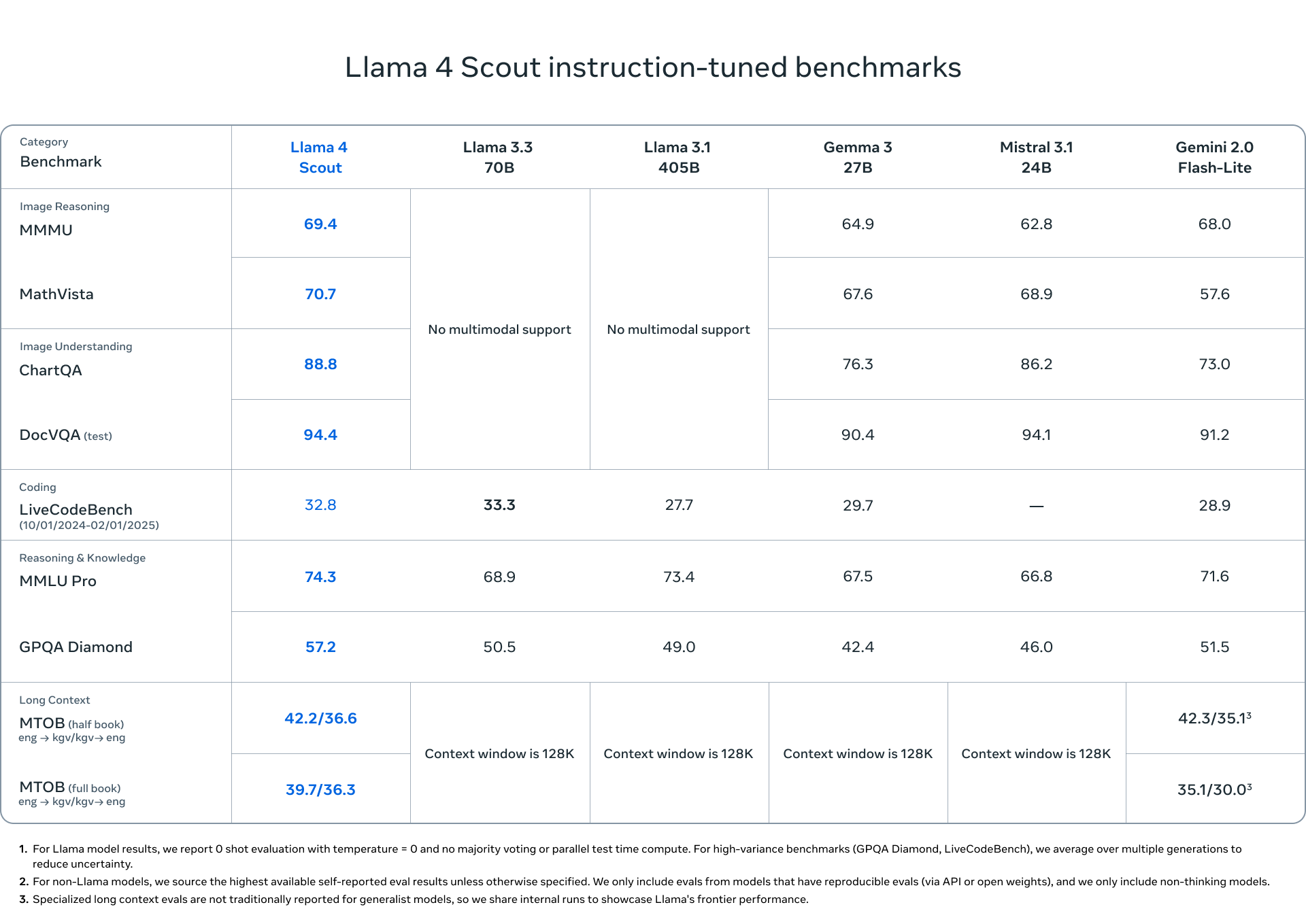
Llama 4 Scout는 170억 개의 활성 매개변수와 16명의 전문가로 구성된 모델입니다. 이는 같은 클래스 내에서 가장 강력한 멀티모달 모델이며, 이전 세대 Llama 모델보다 더 강력합니다. 단일 NVIDIA H100 GPU에 적합하며, 10M의 산업 최고의 문맥 창을 제공하고 다양한 벤치마크에서 Gemma 3, Gemini 2.0 Flash-Lite 및 Mistral 3.1보다 뛰어난 성능을 보입니다.
Llama 4 Maverick는 170억 개의 활성 매개변수와 128명의 전문가로 구성된 모델로, 같은 클래스 내에서 가장 강력한 멀티모달 모델이며, GPT-4o 및 Gemini 2.0 Flash를 능가하고 DeepSeek v3와 비교 가능한 논리적 사고 및 코딩 성능을 보여줍니다. 이는 절반 이하의 활성 매개변수를 사용하며, 실험용 채팅 버전의 ELO 점수는 LMArena에서 1417점을 기록했습니다.
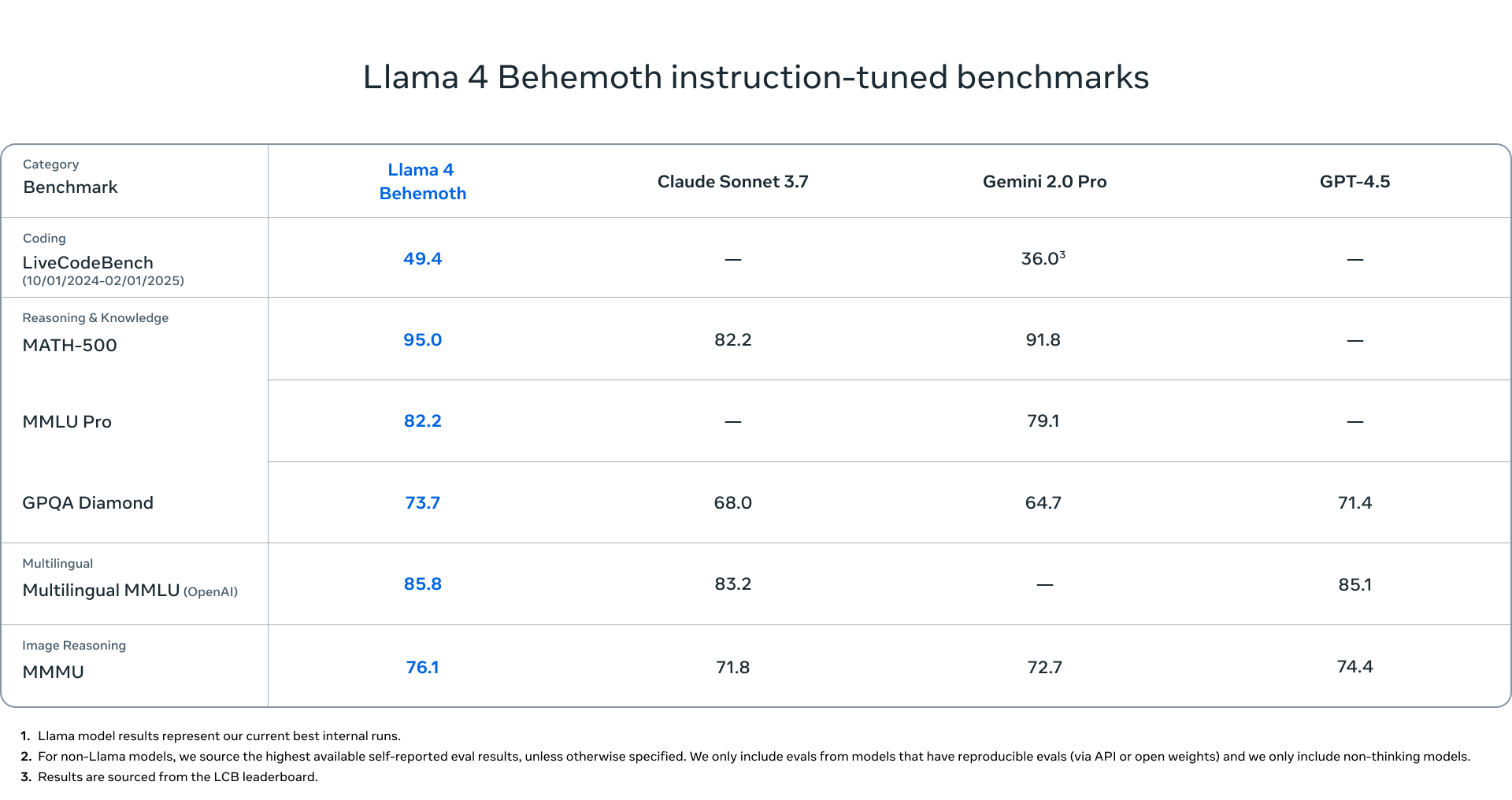
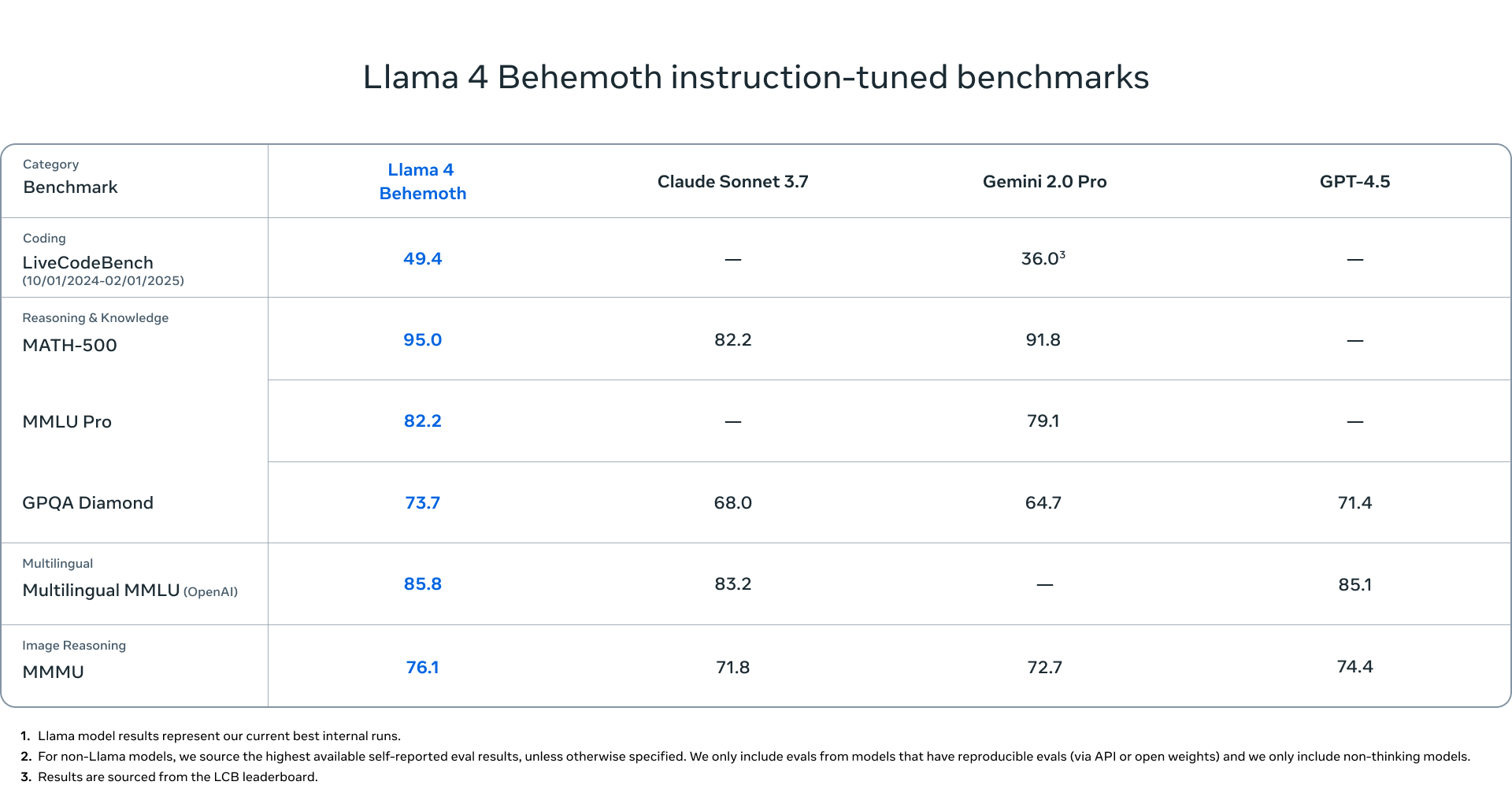
이 모델들은 Llama 4 Behemoth의 지식을 흡수한 결과로 가장 뛰어난 성과를 보입니다. Llama 4 Behemoth는 2880억 개의 활성 매개변수와 16명의 전문가로 구성되어 있으며, 가장 강력한 LLM 중 하나로 알려져 있습니다. 이는 여러 STEM 벤치마크에서 GPT-4.5, Claude Sonnet 3.7 및 Gemini 2.0 Pro를 능가합니다. Llama 4 Behemoth는 아직 훈련 중이지만, 더 많은 세부 정보를 공유할 예정입니다.
오늘은 llama.com과 Hugging Face에서 Llama 4 Scout와 Llama 4 Maverick 모델을 다운로드하세요. WhatsApp, Messenger, Instagram Direct 및 웹에서 Meta AI를 통해 Llama 4를 경험해보세요.
인공지능이 일상 생활을 향상시키는데 점점 더 많이 사용되기 때문에, 선두 모델과 시스템이 개방적으로 제공되어 모든 사람이 개인화된 경험의 미래를 구축할 수 있어야 합니다. 오늘, 우리는 Llama 생태계를 지원하는 가장 정교한 모델 세트를 소개합니다. Llama 4 Scout와 Llama 4 Maverick는 선행된 문맥 길이 지원을 가진 최초의 오픈 웨이트 네이티브 멀티모달 모델이며, 전문가 혼합(MoE) 아키텍처를 처음 사용했습니다. 또한 세계에서 가장 똑똑한 LLM 중 하나인 Llama 4 Behemoth를 미리 공개합니다.
Llama 4 모델은 Llama 생태계의 새로운 시대를 알리는 것입니다. Llama 4 시리즈에서는 두 개의 효율적인 모델을 설계했습니다: Llama 4 Scout는 170억 개의 활성 매개변수와 16명의 전문가가 포함된 모델이며, Llama 4 Maverick는 170억 개의 활성 매개변수와 128명의 전문가로 구성된 모델입니다. 전자는 단일 H100 GPU(Int4 양자화)에 적합하고 후자는 단일 H100 호스트에 적합합니다. 또한 GPT-4.5, Claude Sonnet 3.7 및 Gemini 2.0 Pro를 STEM 중심 벤치마크에서 능가하는 Llama 4 Behemoth 모델을 학습했습니다. MATH-500과 GPQA 다이아몬드와 같은 예시입니다. 현재 Llama 4 Behemoth를 공개하지는 않지만, 더 많은 기술적 세부 정보를 공유할 예정입니다.
개방성은 혁신을 촉진하고 개발자, Meta, 그리고 세계에 좋습니다. 오늘 Llama 4 Scout와 Llama 4 Maverick을 llama.com과 Hugging Face에서 다운로드하여 우리의 최신 기술을 사용하여 새로운 경험을 구축하세요. 또한 곧 파트너를 통해 제공할 예정입니다. 또한 WhatsApp, Messenger, Instagram Direct 및 Meta.AI 웹사이트에서 Meta AI와 Llama 4를 오늘부터 시작해보세요.
이것은 Llama 4 컬렉션의 시작일 뿐입니다. 가장 지능적인 시스템은 일반화된 행동 수행, 인간과의 자연스러운 대화, 그리고 이전에는 본 적 없는 어려운 문제 해결에 능숙해야 합니다. Llama에게 이러한 영역에서 초능력을 부여하면 플랫폼 사용자에게 더 나은 제품을 제공하고 개발자가 다음 큰 소비자 및 비즈니스 사례에서 혁신할 수 있는 기회가 될 것입니다. 우리는 모델과 제품 모두를 계속해서 연구하고 프로토타입을 제작하며, LlamaCon 4월 29일 더 많은 정보를 공유하겠습니다—더 듣고 싶으시면 신청해주세요.
Llama 4 Scout와 Llama 4 Maverick는 개발자, 기업 및 AI의 잠재적 용도와 혜택에 대한 호기심을 가진 모든 사람들에게 제품에 다음 세대 지능을 추가하는 최고의 선택입니다. 오늘 우리는 이 모델들의 네 가지 주요 부분과 그들의 개발 과정에 대한 통찰력에 대해 더 많은 내용을 공유합니다. 또한 우리의 새로운 Llama 4 모델로 커뮤니티가 만들어낼 놀라운 새로운 경험을 기대하고 있습니다.
사전 학습
이 모델들은 Llama의 최선을 제공하며, 크기가 훨씬 큰 모델들을 능가하면서 매력적인 가격에 멀티모달 지능을 제공합니다. 다음 세대 Llama 모델을 구축하기 위해 사전 학습 중에 여러 새로운 접근 방식을 채택해야 했습니다.
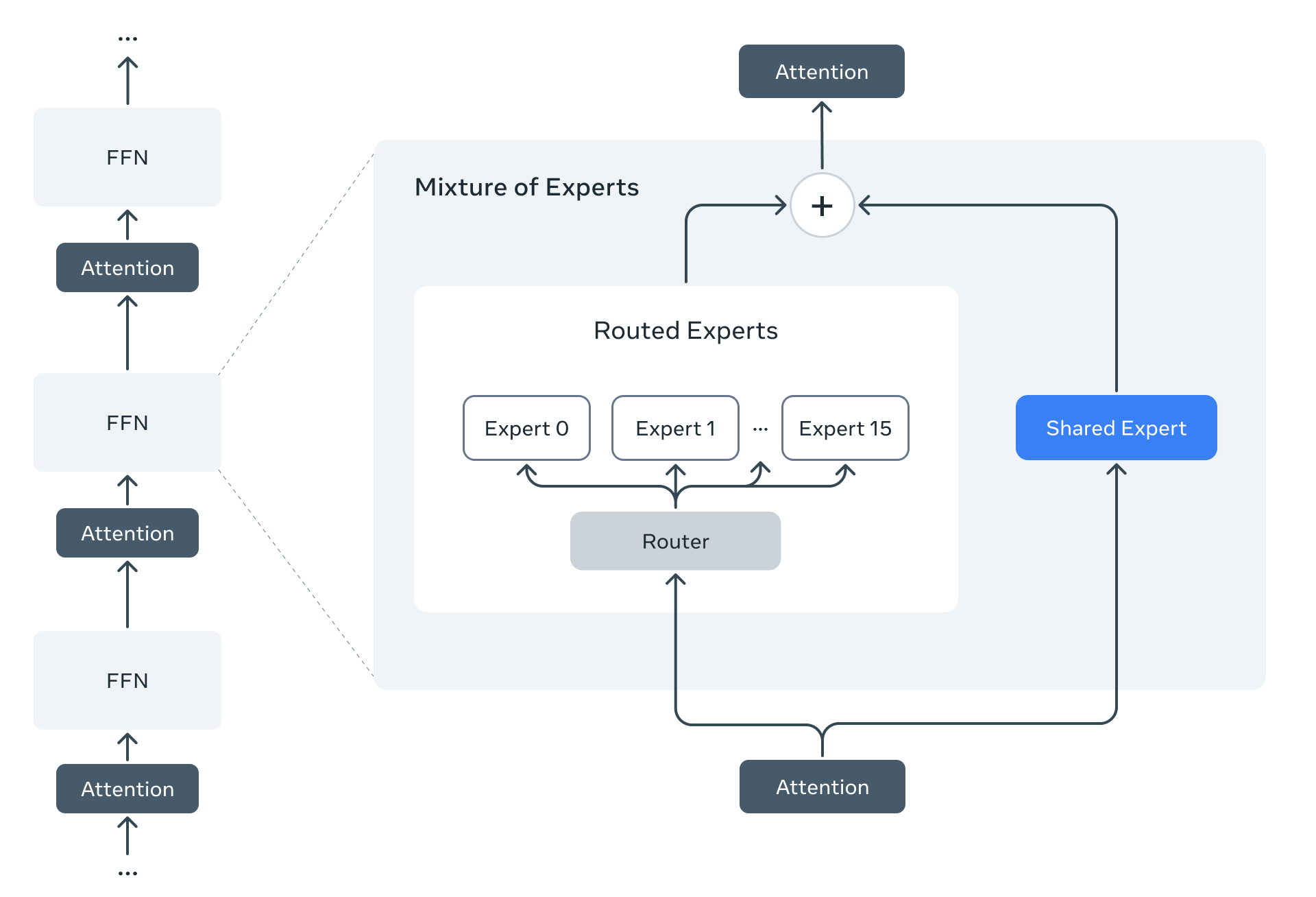
새로운 Llama 4 모델은 전문가 혼합(MoE) 아키텍처를 사용하는 첫 번째 모델입니다. MoE 모델에서는 단일 토큰이 총 매개변수의 일부만 활성화합니다. MoE 아키텍처는 학습과 추론 모두에서 계산 효율이 더 높으며, 고정된 학습 FLOPs 예산을 고려할 때 밀집 모델보다 높은 품질을 제공합니다.
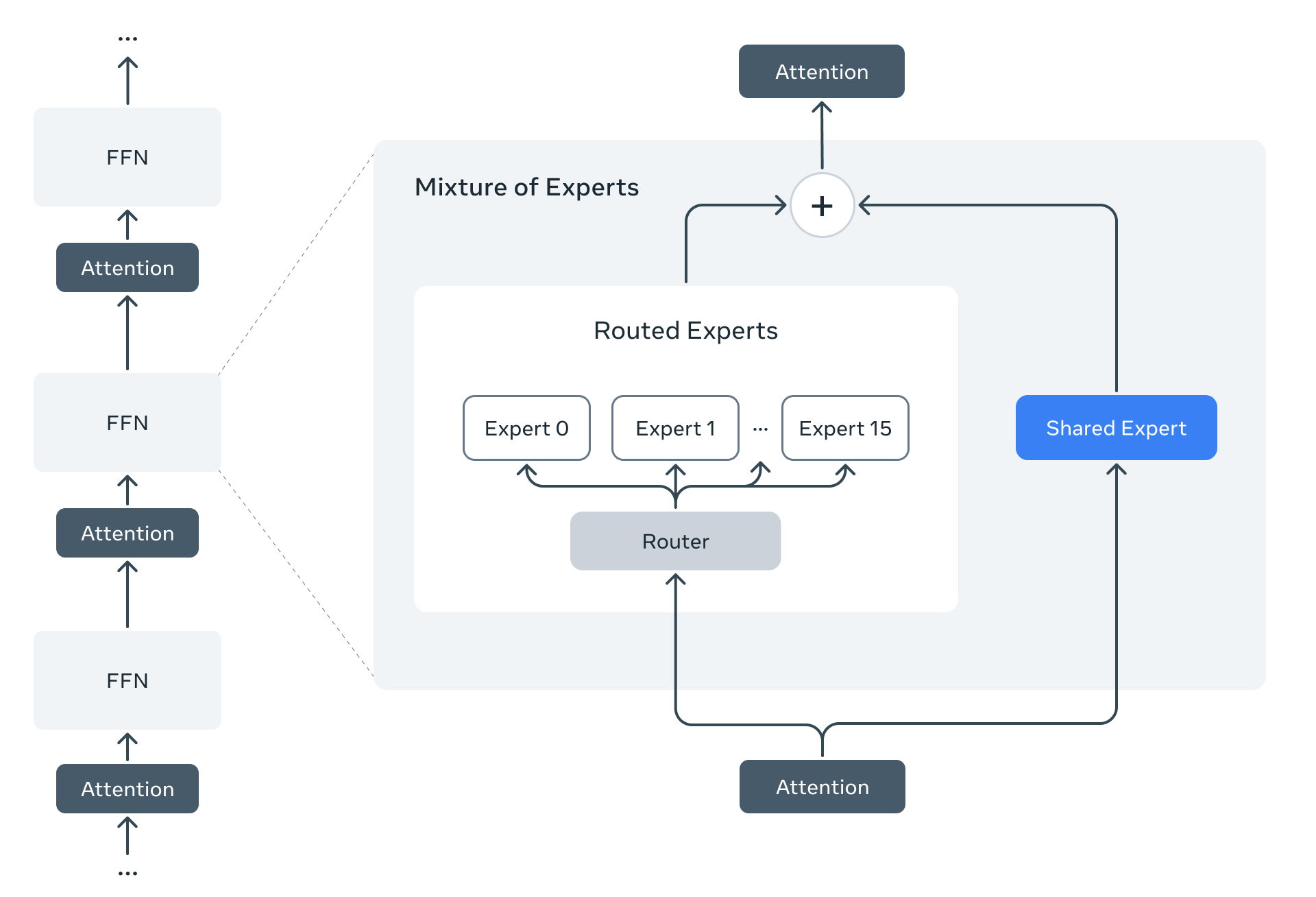
예시로, Llama 4 Maverick 모델은 170억 개의 활성 매개변수와 4000억 개의 총 매개변수를 가지고 있습니다. 우리는 추론 효율을 높이기 위해 밀집 계층과 전문가 혼합(MoE) 계층을 번갈아 사용합니다. MoE 계층은 128개의 라우팅된 전문가와 공유된 전문가를 사용하며, 각 토큰이 공유된 전문가와 동시에 128개 라우팅된 전문가 중 하나로 전송됩니다. 따라서 모든 매개변수가 메모리에 저장되어 있지만, 이 모델을 제공할 때 활성화되는 매개변수는 총 매개변수의 일부만입니다. 이는 추론 효율을 높여 모델 서비스 비용과 지연 시간을 줄이며, Llama 4 Maverick는 단일 NVIDIA H100 DGX 호스트에서 쉽게 배포하거나 분산 추론을 통해 최대 효율성을 달성할 수 있습니다.
Llama 4 모델은 내재적인 멀티모달 기능을 갖추고 있으며, 텍스트와 비전 토큰을 통합된 모델 백본에 원활하게 통합하기 위해 초기 융합을 도입했습니다. 초기 융합은 큰 양의 라벨 없는 텍스트, 이미지 및 영상 데이터를 사용하여 모델을 공동으로 사전 학습할 수 있게 하여 중요한 발전입니다. 또한 Llama 4의 비전 인코더를 개선했으며, 이는 MetaCLIP 기반이지만 동결된 Llama 모델과 함께 별도로 학습되어 인코더가 LLM에 더 잘 적응하도록 했습니다.
우리는 다양한 배치 크기, 모델 너비, 깊이 및 학습 토큰 값에서 잘 전달되는 초록색 하이퍼파라미터를 설정할 수 있게 하는 새로운 훈련 기법인 MetaP를 개발했습니다. Llama 4는 200개 언어로 사전 학습하여 개방형 소스코드 미세 조정 작업을 가능하게 했으며, 각 언어에는 약 10억 토큰이 포함되어 있고, 총 10배 더 많은 다국어 토큰을 포함한 Llama 3에 비해 10배 더 많은 다국어 토큰을 제공합니다.
또한 우리는 FP8 정밀도를 사용한 효율적인 모델 학습에 집중하며 품질을 희생하지 않고 높은 모델 FLOPs 활용을 보장했습니다. FP8과 32K GPU를 사용하여 Llama 4 Behemoth 모델을 사전 학습하면서, 1GPU당 390 TFLOPs의 성능을 달성했습니다. 전체 학습 데이터 혼합물은 약 30조 토큰으로 구성되었으며, 이는 Llama 3 사전 학습 혼합물의 두 배 이상이며 다양한 텍스트, 이미지 및 영상 데이터셋을 포함합니다.
우리는 "중간 훈련"을 통해 모델의 핵심 기능을 새로운 학습 레시피와 함께 개선할 수 있도록 계속 훈련했습니다. 여기에는 전문화된 데이터세트를 사용하여 긴 문맥 확장도 포함됩니다. 이를 통해 Llama 4 Scout의 품질을 향상시키고, 1000만 입력 컨텍스트 길이를 위한 최상의 성능을 달성할 수 있었습니다.
새로운 모델의 후학습
최신 모델은 다양한 사용 사례와 개발자 요구를 충족시키기 위해 작은 옵션과 큰 옵션을 제공합니다. Llama 4 Maverick는 이미지와 텍스트 이해에서 비견될 수 없는 산업 최첨단 성능을 제공하여 언어 장벽을 넘어서는 고급 AI 응용 프로그램을 만들 수 있습니다. 일반적으로 도우미와 챗봇 사용 사례에 대해 강력한 모델로 자리매김하고 있는 Llama 4 Maverick는 정밀한 이미지 이해와 창의적인 글쓰기에 매우 적합합니다.
Llama 4 Maverick 모델을 후학습하는 과정에서 여러 입력 모달리티, 추론 능력, 대화 능력을 유지하는 균형을 맞추는 것이 가장 큰 도전 과제였습니다. 모달리티를 혼합하기 위해 개별 모달리티 전문가 모델보다 성능을 희생하지 않으면서 신중하게 구성된 커리큘럼 전략을 세웠습니다. Llama 4에서는 경량화된 지도 학습(supervised fine-tuning, SFT) > 온라인 강화 학습(online reinforcement learning, RL) > 경량화된 직접 선호도 최적화(direct preference optimization, DPO)의 다양한 접근 방식을 채택하여 후학습 파이프라인을 개선했습니다. 중요한 교훈은 SFT와 DPO가 모델을 과하게 제약할 수 있으며 온라인 RL 단계에서 탐색을 제한하고, 특히 추론, 코딩 및 수학 분야에서는 최적의 정확도를 저해할 수 있다는 점입니다. 이를 해결하기 위해 Llama 모델을 심판으로 사용하여 쉬운 것으로 태그가 붙은 데이터를 50% 이상 제거하고 남은 어려운 데이터셋에 대해 경량화된 SFT를 수행했습니다. 이후 멀티모달 온라인 RL 단계에서는 신중하게 어려운 프롬프트를 선택함으로써 성능의 큰 개선을 이루었습니다. 또한 중등도에서 어려움으로 난이도를 가진 프롬프트를 필터링하고 유지하는 지속적인 온라인 RL 전략을 도입했습니다. 이는 연산량과 정확성 간의 균형을 잘 맞추는 데 매우 유익한 것으로 입증되었습니다. 그런 다음 경량화된 DPO를 통해 모델 응답 품질에 관련된 모서리 사례를 처리하여, 모델의 지능성과 대화 능력을 적절히 조화롭게 만들었습니다.
이러한 파이프라인 아키텍처와 적응형 데이터 필터링을 포함한 지속적인 온라인 RL 전략은 산업 최첨단 일반 목적 대화 모델로 이어졌으며, 이는 최신 인공지능과 이미지 이해 기능을 갖추고 있습니다.
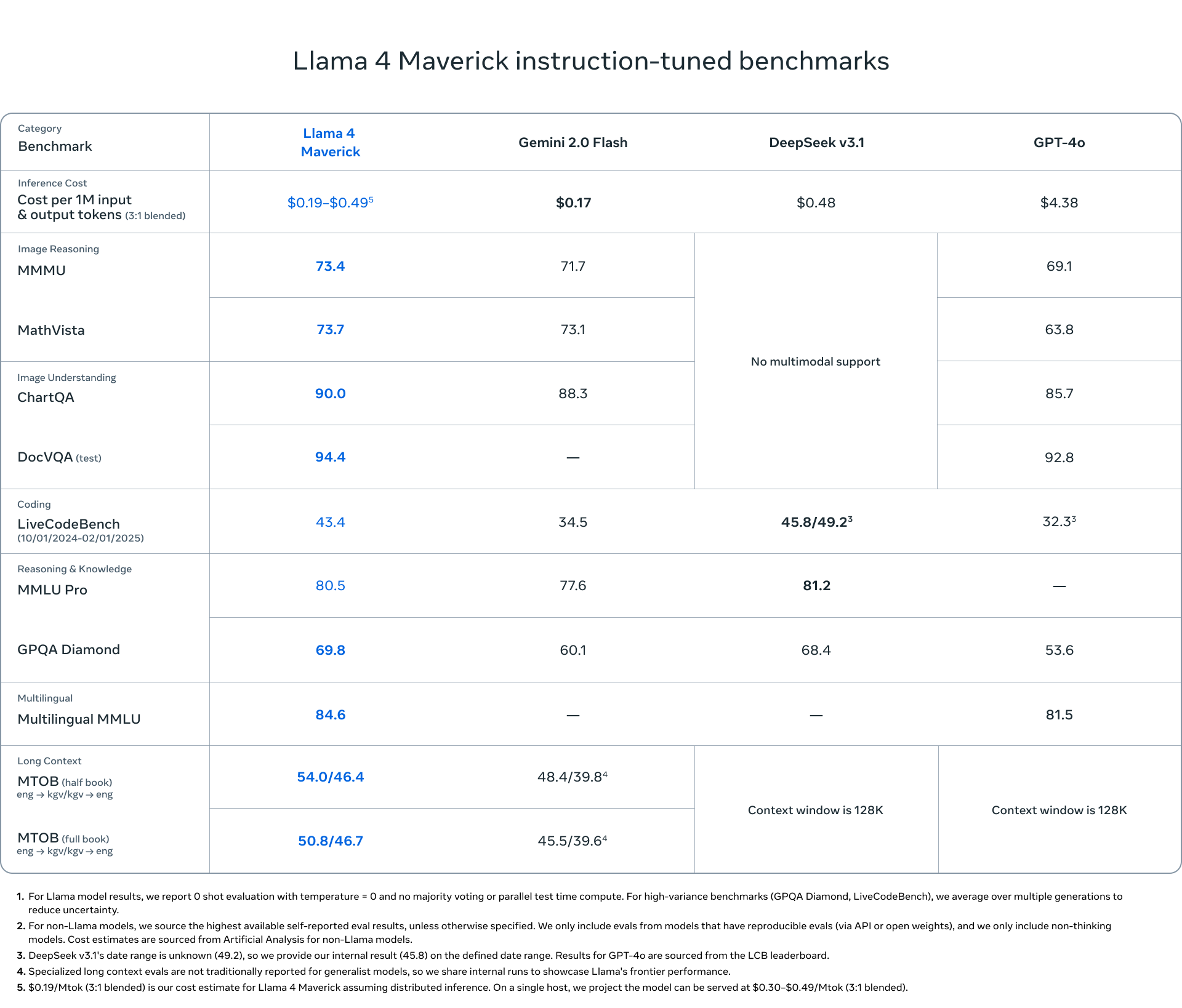
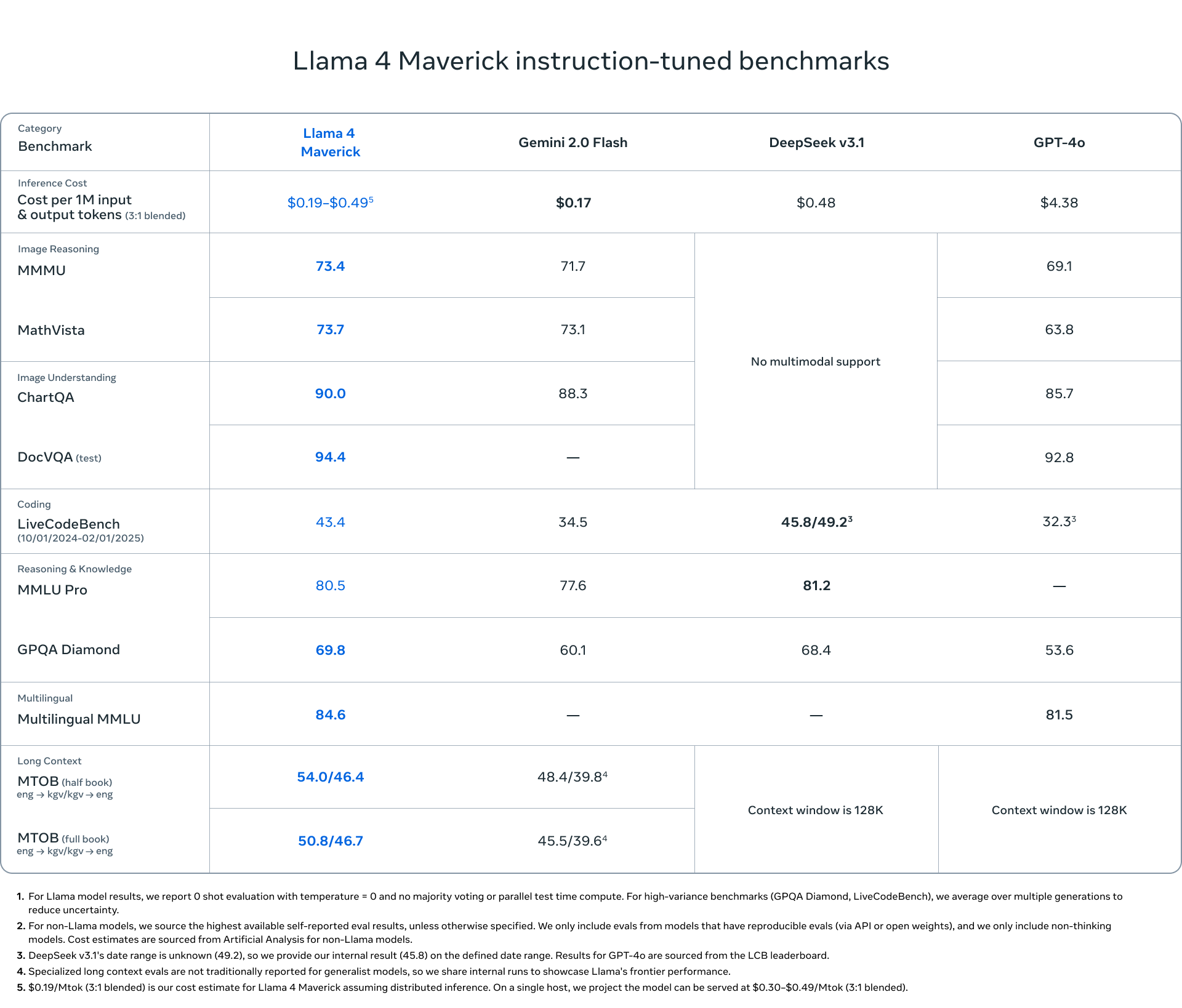
일반 목적으로 사용되는 Llama 4 Maverick는 170억 개의 활성 매개변수, 128개의 전문가 및 총 4000억 개의 매개변수를 포함하고 있으며, 이는 Llama 3.3 70B에 비해 높은 품질을 더 저렴한 가격에 제공합니다. Llama 4 Maverick는 GPT-4o와 Gemini 2.0과 같은 동등한 모델보다 코딩, 추론, 다언어, 긴 문맥 및 이미지 벤치마크에서 더 나은 성능을 발휘하며, 훨씬 큰 DeepSeek v3.1에 맞먹는 코딩 및 추론 성능을 자랑합니다.
Llama 4 Scout 모델
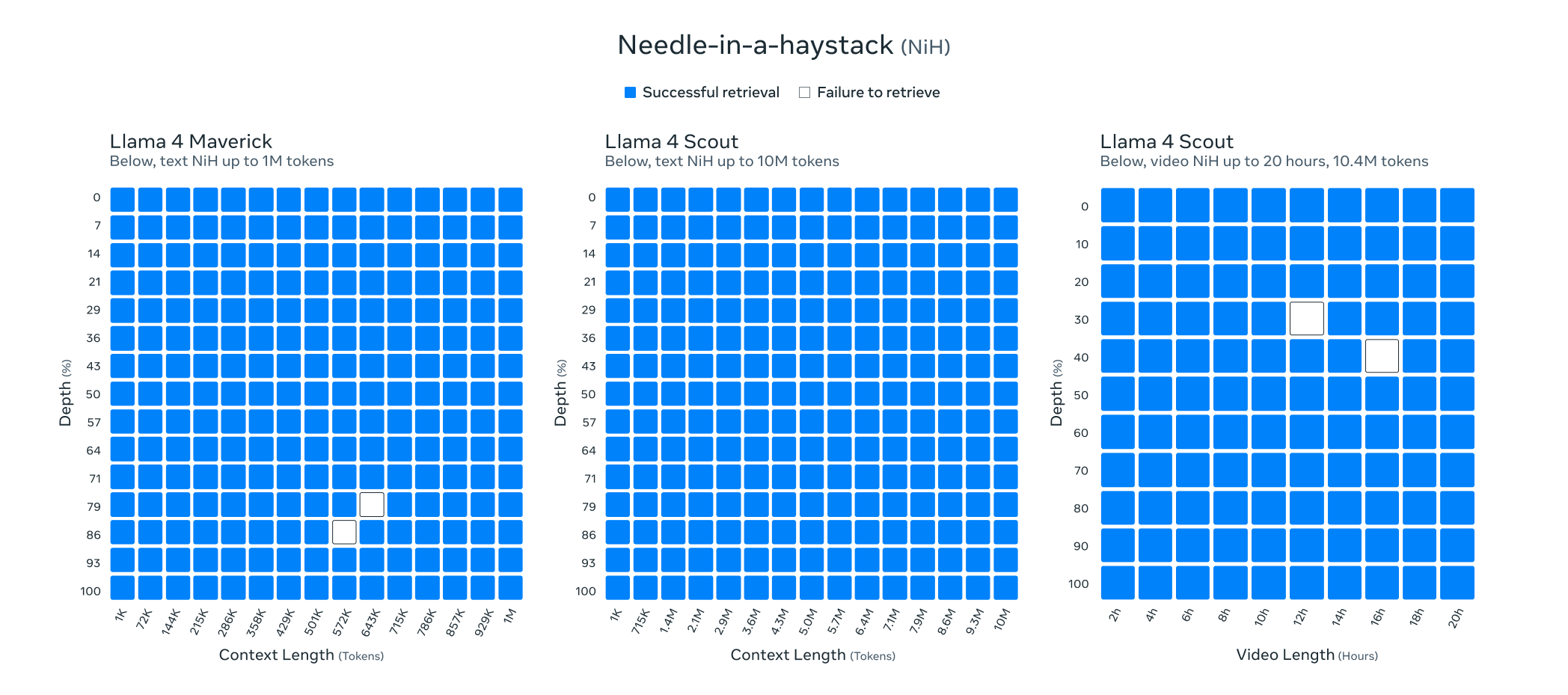
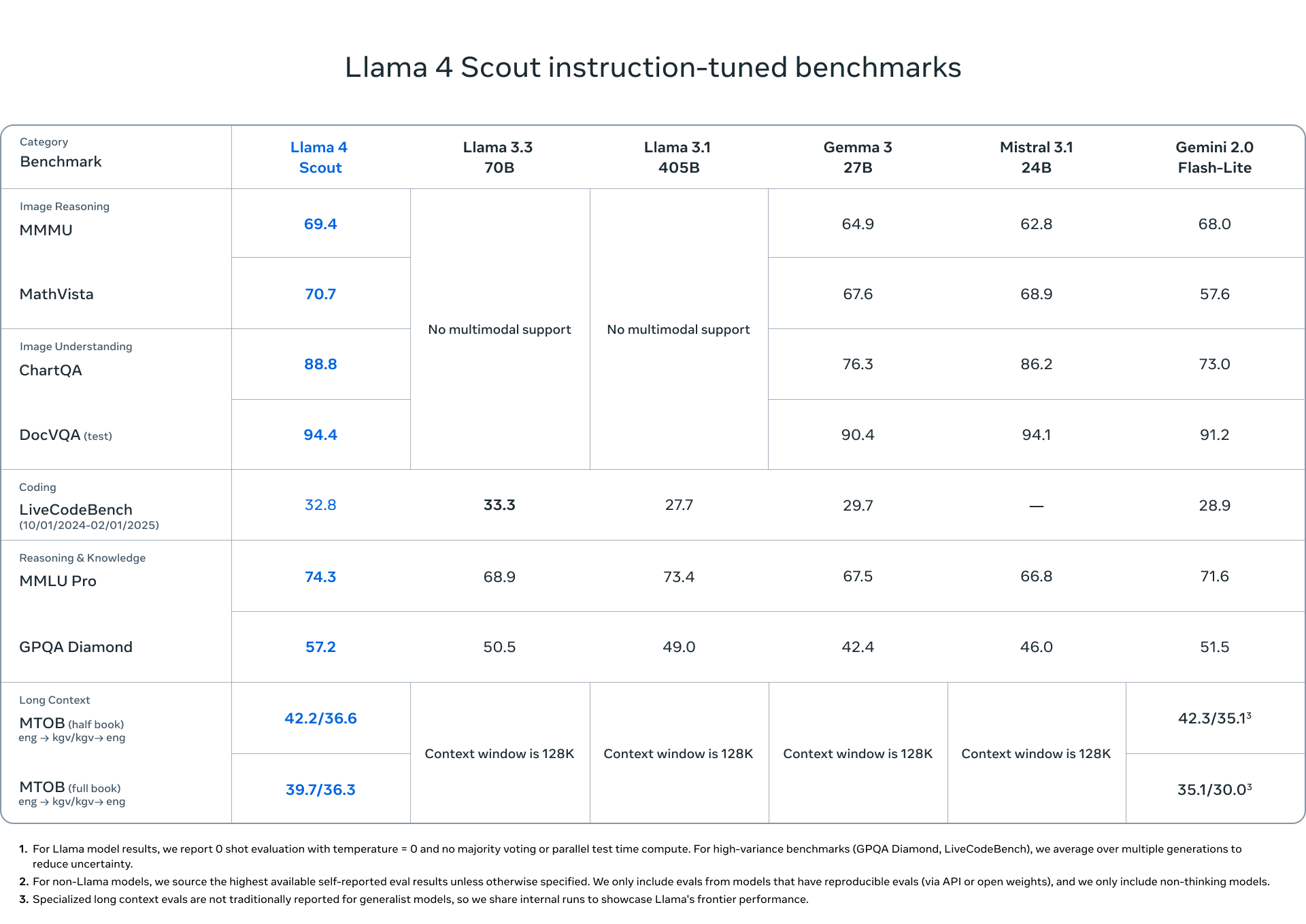
우리는 Llama 4 Scout라는 작은 모델을 제공합니다. 이 모델은 170억 개의 활성 매개변수와 16개의 전문가를 포함하며, 총 1090억 개의 매개변수를 갖추고 있어 그 클래스에서 최첨단 성능을 자랑합니다. Llama 4 Scout는 Llama 3의 128K에서 산업 최고의 1000만 토큰으로 지원되는 문맥 길이를 크게 증가시킵니다. 이는 다중 문서 요약, 광범위한 사용자 활동 분석을 통한 개인화된 작업 수행, 그리고 방대한 코드베이스에 대한 추론과 같은 다양한 가능성을 열어줍니다.
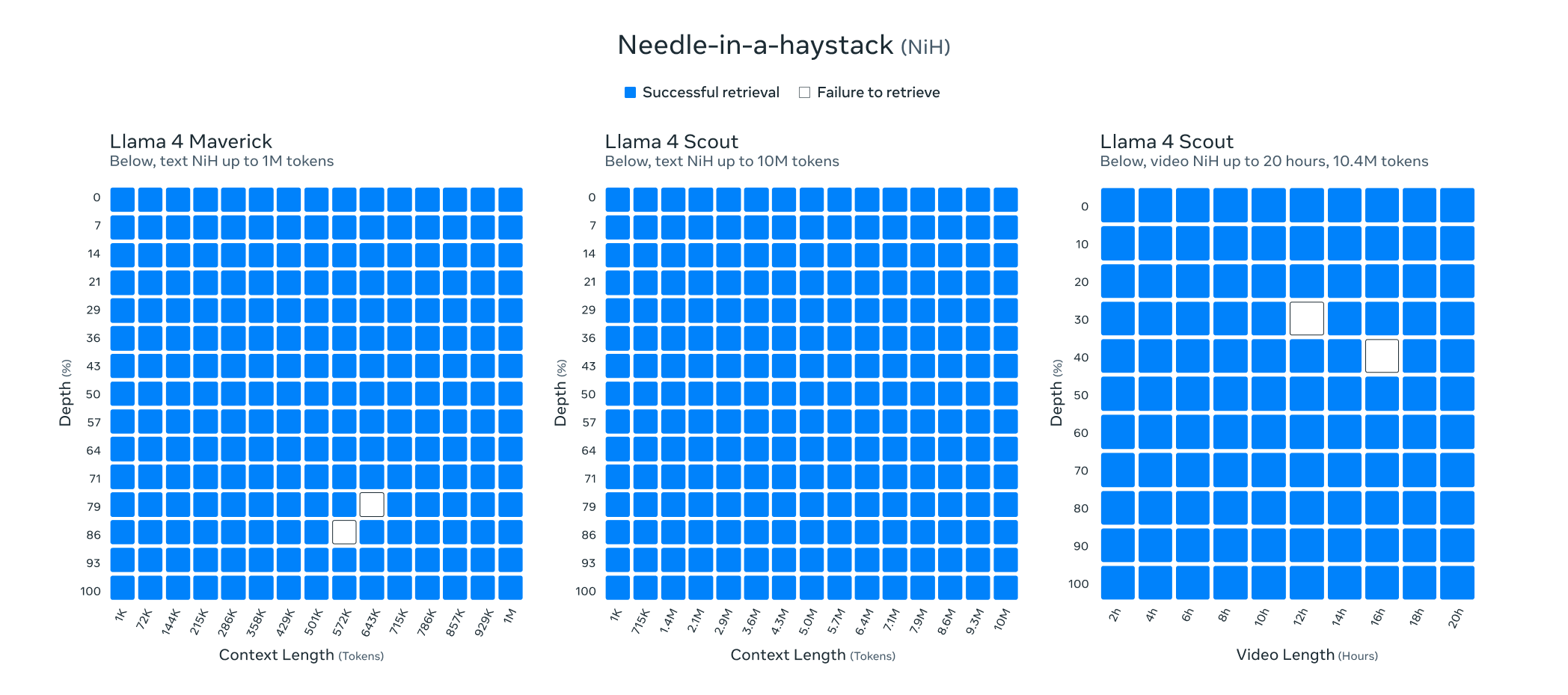
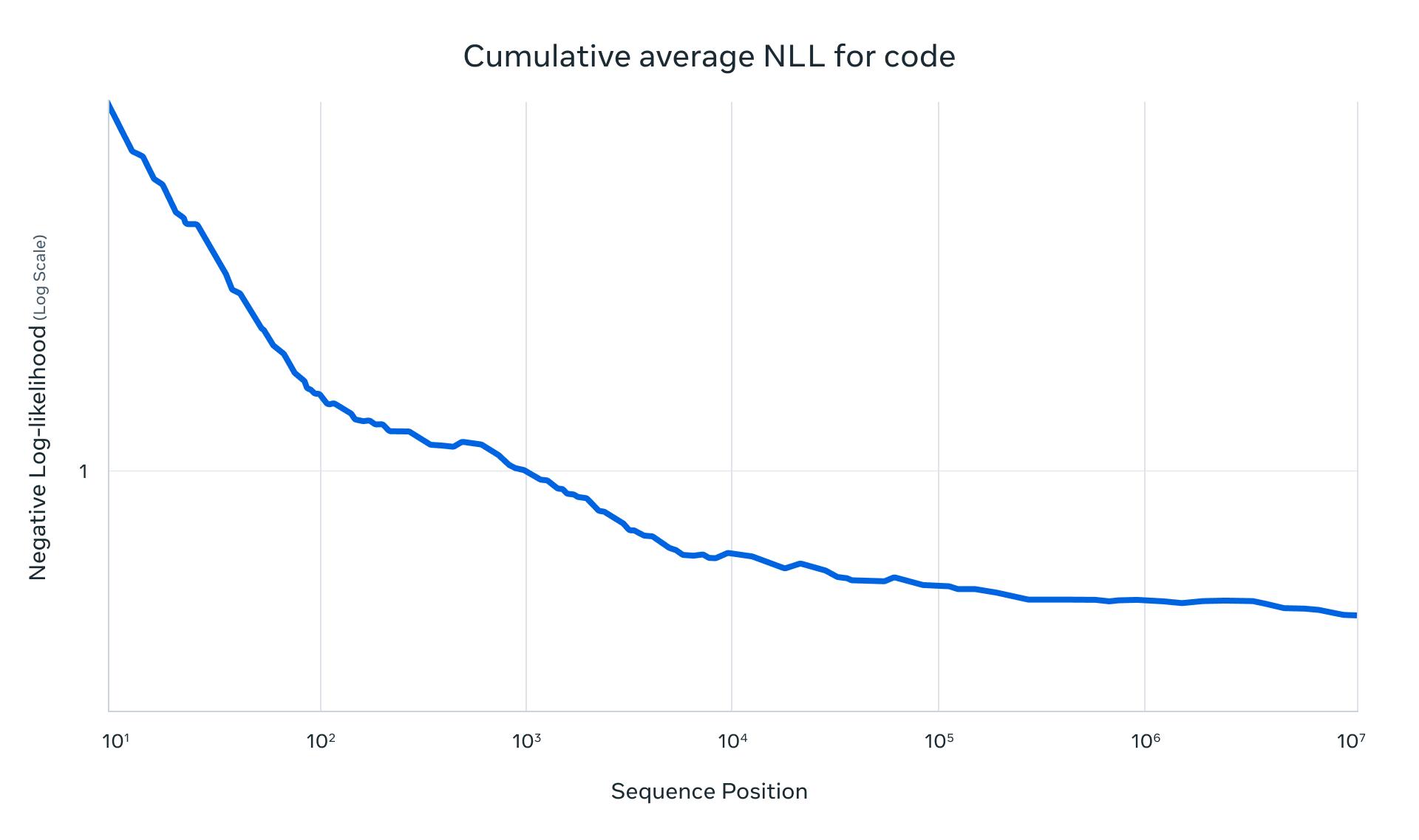
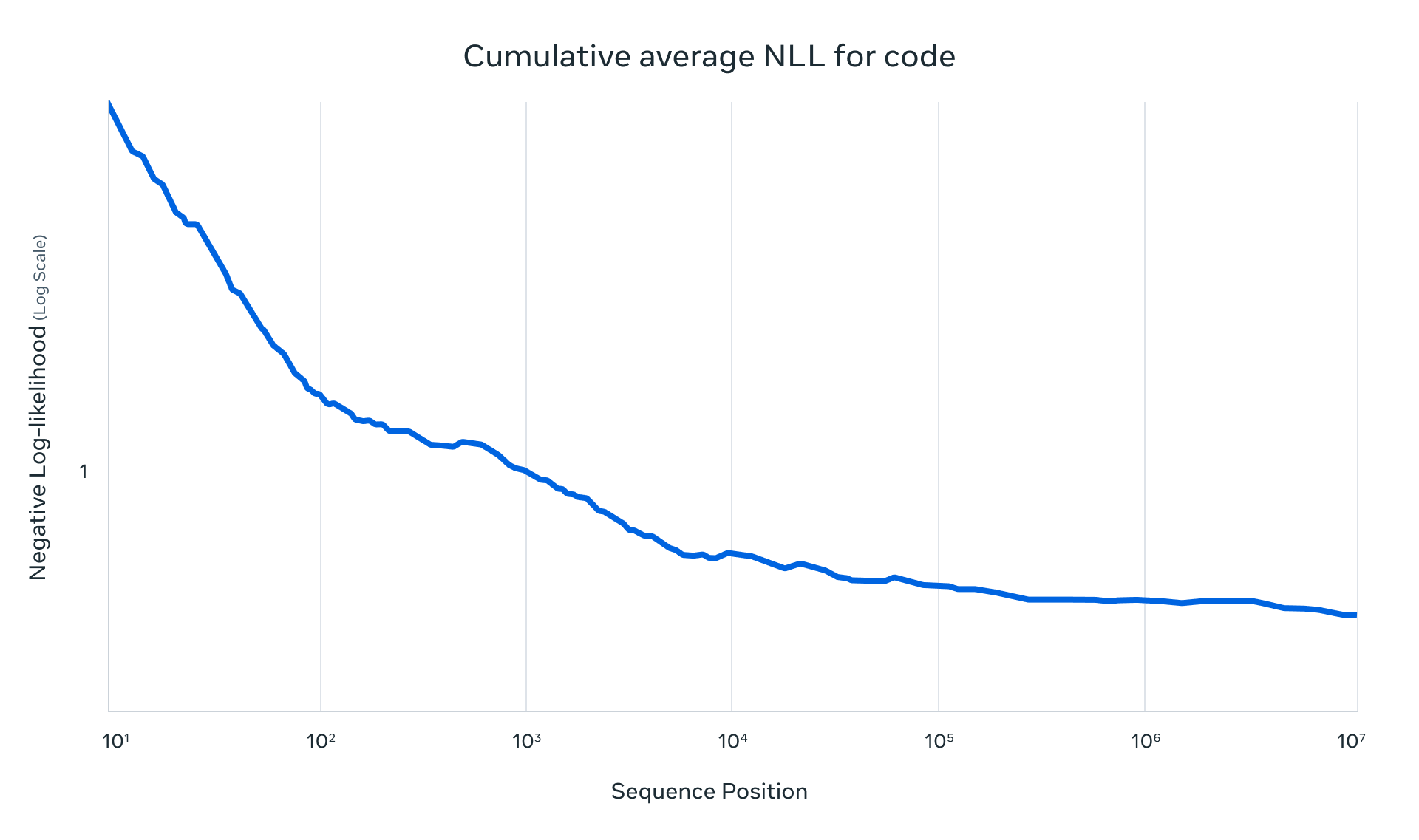
Llama 4 Scout는 256K 문맥 길이로 사전 학습 및 사후 학습이 이루어졌으며, 이는 기본 모델에 고급 길이 일반화 능력을 부여합니다. 우리는 "텍스트에서 '바늘 찾기'"와 같은 작업 및 코드 토큰 1000만 개에 대한 누적 음의 로그 가능성(NLLs) 등을 포함한 다양한 작업에서 강력한 결과를 제시합니다. Llama 4 아키텍처의 주요 혁신은 포지셔널 임베딩이 없는 교차 주의를 사용한 것입니다. 또한 추론 시 주의의 온도 스케일링을 사용하여 길이 일반화를 강화했습니다. 이 것을 iRoPE 아키텍처라고 부르며, "i"는 "교차" 주의를 의미하며, 장기적으로는 "무한" 문맥 길이를 지원하는 것을 목표로 하고 있습니다. "RoPE"는 대부분의 레이어에서 사용되는 로테이션 포지션 임베딩을 의미합니다.
우리는 두 모델 모두 시간 활동과 관련 이미지를 포함한 폭넓은 시각적 이해를 제공하기 위해 다양한 이미지 및 비디오 프레임 스틸에 대해 훈련시켰습니다. 이를 통해 시각적 추론 및 작업 이해를 위한 텍스트 프롬프트와 함께 다중 이미지 입력에서 쉽게 상호작용할 수 있습니다. 모델은 최대 48개의 이미지에 대해 사전 훈련되었으며, 사후 훈련에서 최대 8개의 이미지에 대해 좋은 결과를 얻었습니다.
Lama 4 Scout은 또한 이미지 기반에서 동급 최고 수준을 자랑하며, 사용자 프롬프트를 관련 시각적 개념과 일치시키고 이미지 내 영역에 대한 모델 응답을 고정할 수 있습니다. 이를 통해 LLM은 사용자 의도를 더 잘 이해하고 관심 있는 객체를 현지화할 수 있도록 보다 정밀한 시각적 질문 응답을 제공합니다. 또한 Lama 4 Scout은 코딩, 추론, 긴 컨텍스트 및 이미지 벤치마크에서 유사한 모델을 능가하며 이전의 모든 Lama 모델보다 더 강력한 성능을 제공합니다.
이 새로운 모델들은 인간 연결의 미래를 가능하게 하는 중요한 구성 요소입니다. 오픈 소스에 대한 우리의 약속에 따라, 저희는 Lama 4 매버릭과 Lama 4 Scout을 llama.com 과 허깅 페이스에서 다운로드할 수 있도록 하고 있으며, 가장 널리 사용되는 클라우드 및 데이터 플랫폼, 엣지 실리콘, 글로벌 서비스 통합업체들도 곧 출시할 예정입니다.
라마를 새로운 크기로 밀어붙이기: 2T 거대 기업
Lama 4 Behemoth의 미리보기를 공유하게 되어 매우 기쁩니다. Lama 4 Behemoth는 288B개의 활성 매개변수, 16명의 전문가, 그리고 거의 2조 개의 총 매개변수를 가진 다중 모달 전문가 혼합 모델입니다. 수학, 다중 언어성, 이미지 벤치마크에서 비이성적인 모델을 위한 최첨단 성능을 제공하는 이 모델은 더 작은 Lama 4 모델을 가르치기에 완벽한 선택이었습니다. 우리는 Lama 4 Behemoth의 Lama 4 Maverick 모델을 교사 모델로 코드화하여 최종 과제 평가 지표 전반에서 상당한 품질 향상을 이루었습니다. 우리는 훈련을 통해 소프트 타겟과 하드 타겟에 동적으로 가중치를 부여하는 새로운 증류 손실 함수를 개발했습니다. Lama 4 Behemoth의 사전 훈련 중 코드화는 학생 훈련에 사용되는 대부분의 훈련 데이터에 대해 증류 목표를 계산하는 데 필요한 자원 집약적인 전방 패스의 계산 비용을 상각합니다. 학생 훈련에 통합된 추가적인 새로운 데이터를 위해, 우리는 Behemoth 모델에 대한 전방 패스를 실행하여 증류 목표를 생성했습니다.
주요 포인트
우리는 두조 트릴리온 개의 매개변수를 가진 모델을 후기 학습하는 데 상당한 도전을 겪었습니다. 이는 데이터를 포함한 레시피를 완전히 재정비해야 했습니다. 성능을 극대화하기 위해 우리는 더 작은 모델의 경우 50%였던 것을 95%로 줄였으며, 품질과 효율성에 중점을 두기 위해 SFT 데이터의 95%를 제거했습니다.
경량 SFT에 이어 대규모 강화 학습(RL)을 수행함으로써, 추론 및 코딩 능력에서 더 큰 성능 개선을 이끌어냈습니다. 우리의 RL 레시피는 정책 모델을 사용한 패스@k 분석으로 어려운 프로프트를 샘플링하는 데 중점을 두었습니다. 또한 훈련 과정에서 0의 이득을 가진 프로프트를 동적으로 필터링하고, 여러 능력에서 혼합된 프로프트로 구성된 배치로 훈련하는 것이 수학, 추론 및 코딩에서의 성능 향상에 중요한 역할을 했습니다.
다양한 시스템 지침을 샘플링하는 것이 모델이 추론 및 코딩 능력에 대한 명령어를 따르는 능력을 유지하고 다양한 작업에서 잘 수행할 수 있도록 하는 데 결정적이었다는 것을 발견했습니다. 또한 Llama 4의 RL 스케일링은 이전 세대와 비교해 10배 더 높은 학습 효율을 제공하였습니다.
보안과 보호
우리는 가장 도움이 되고 유용한 모델을 개발하면서도 가장 심각한 위험으로부터 보호하고 완화하는 데 중점을 두고 있습니다. 우리는 Llama 4를 개발할 때 AI 보호에 대한 최선의 관행을 통합했습니다.
이러한 접근 방식에는 전처리부터 후기 학습까지 각 단계에서 적응형 시스템 수준의 완화 전략을 포함하여 모델 개발 과정에서 적대적 사용자로부터 개발자를 보호하는 것이 포함됩니다. 이를 통해 개발자들은 Llama 지원이 되는 애플리케이션을 위해 유용하고 안전한 경험을 만들 수 있습니다.
전처리와 후기 학습 완화
전처리 단계에서는 다양한 데이터 완화 기법을 조합하여 모델을 안전하게 보호합니다. 후기 학습 단계에서는 정책에 부합하는 모델을 보장하기 위한 다양한 기술을 적용하여 사용자와 개발자에게 유용한 데이터를 제공합니다.
시스템 수준 접근 방식
시스템 수준에서는 Llama 모델과 기타 제3자 도구와 통합할 수 있는 여러 가지 오픈 소스 보호 장치를 공개했습니다. 예를 들어, Llama Guard, Prompt Guard 및 CyberSecEval 등입니다. 개발자는 이러한 도구를 사용하여 특정 애플리케이션에 맞는 최적의 안전 경험을 구축할 수 있습니다.
평가 및 적대적 검증
우리는 다양한 시나리오와 사용 사례에서 제어된 방법으로 모델을 체계적으로 테스트하여 후기 학습에 다시 피드백합니다. 자동화 및 수동 테스트를 통한 다양한 주제를 대상으로 모델의 위험을 이해하고 평가하기 위해 고안한 GOAT는 효율적이고 효과적인 프로세스와 함께 양적 및 질적 위험에 대한 포괄적인 그림을 제공합니다.
대형 언어 모델(LLM) 내 편향 문제 해결
LLM이 역사적으로 논란이 되는 정치적 및 사회적 주제에 대해 좌편향되는 문제를 알고 있으며, 이를 줄이기 위해 노력하고 있습니다. Llama 4는 Llama 3보다 논란이 되는 정치적 및 사회적 주제에서 거부하는 비율이 현저히 낮아졌으며, Grok와 동일한 수준으로 편향 없는 응답을 제공합니다.
Llama 생태계 탐색
지능적인 모델과 더불어 개인화되고 인간처럼 빠른 속도로 응답할 수 있는 모델도 필요하다는 점을 강조하고 있습니다. Llama 4는 이러한 요구를 충족시키기 위해 최적화되었습니다.
Llama 4 Scout 및 Llama 4 Maverick 모델은 현재 llama.com과 Hugging Face에서 다운로드할 수 있으며, WhatsApp, Messenger, Instagram Direct 및 Meta.AI 웹사이트에서 Meta AI를 사용하여 Llama 4를 경험해볼 수 있습니다.
이 작업은 AI 커뮤니티의 파트너들의 지원이 있었습니다. 이 작업에 기여한 파트너사를 다음과 같이 감사드립니다: Accenture, Amazon Web Services, AMD, Arm, CentML, Cerebras, Cloudflare, Databricks, Deepinfra, DeepLearning.AI, Dell, Deloitte, Fireworks AI, Google Cloud, Groq, Hugging Face, IBM Watsonx, Infosys, Intel, Kaggle, Mediatek, Microsoft Azure, Nebius, NVIDIA, ollama, Oracle Cloud, PwC, Qualcomm, Red Hat, SambaNova, Sarvam AI, Scale AI, Scaleway, Snowflake, TensorWave, Together AI, vLLM, Wipro.
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

 아이언우드: 추론의 시대를 위한 최초의...
아이언우드: 추론의 시대를 위한 최초의...
 Apple, M4 Max 및 새로운 M3 Ultra...
Apple, M4 Max 및 새로운 M3 Ultra...

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
**Gemini 2.5 pro 요약본입니다.
Llama 4 모델 시리즈 요약: 네이티브 멀티모달 AI 혁신의 시작
Meta AI는 새로운 Llama 4 모델 시리즈를 발표했습니다. 이 모델들은 텍스트, 이미지 등 다양한 데이터를 처음부터 함께 처리하는 네이티브 멀티모달 기능과 효율적인 전문가 혼합(MoE: Mixture-of-Experts) 아키텍처를 특징으로 합니다.
주요 발표 내용:
Llama 4 Scout:
170억 개 활성 파라미터, 16개 전문가 구성.
동급 최고 성능의 멀티모달 모델이며, 이전 세대 Llama 모델보다 강력함.
단일 NVIDIA H100 GPU에 탑재 가능.
업계 최고 수준인 1,000만 토큰의 컨텍스트 길이 지원.
주요 벤치마크에서 Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1 등 모델보다 우수한 성능.
Llama 4 Maverick:
170억 개 활성 파라미터, 128개 전문가 구성.
동급 최고 성능 멀티모달 모델로, GPT-4o, Gemini 2.0 Flash 등을 능가.
더 적은 활성 파라미터로 DeepSeek v3와 유사한 추론 및 코딩 성능 달성.
비용 대비 성능 비율이 우수 (실험적 채팅 버전 LMArena ELO 1417점).
Llama 4 Behemoth (미리보기):
2,880억 개 활성 파라미터, 16개 전문가, 총 약 2조 개 파라미터.
Scout와 Maverick을 훈련시킨 '교사' 모델로, Meta의 가장 강력한 모델 중 하나.
여러 STEM 벤치마크에서 GPT-4.5, Claude Sonnet 3.7, Gemini 2.0 Pro 등 능가.
현재 훈련 중이며 아직 출시되지 않음.
핵심 기술 및 특징:
네이티브 멀티모달리티: 텍스트와 시각 정보를 통합하는 '초기 융합(early fusion)' 방식을 사용하여 대규모 데이터로 공동 사전 훈련.
MoE 아키텍처: 훈련 및 추론 효율성을 높여 고성능 제공.
긴 컨텍스트: Scout 모델은 1,000만 토큰 컨텍스트 지원 (iRoPE 아키텍처 등 혁신 기술 적용).
향상된 훈련: FP8 정밀도 사용, 30조 개 이상의 토큰(텍스트, 이미지, 비디오 포함)으로 훈련, 새로운 하이퍼파라미터 설정 기술(MetaP), 개선된 후처리 파이프라인(SFT, RL, DPO) 적용.
안전성 및 편향성 완화: 모델 개발 전 과정에 안전 조치 통합, Llama Guard 등 오픈 소스 안전 도구 제공, 편향성 감소 노력 (정치/사회적 주제 답변 거부율 감소 및 균형 개선).
오픈 소스 및 접근성:
Llama 4 Scout와 Maverick 모델은 오픈 웨이트(open-weight)로 공개되어 llama.com과 Hugging Face에서 다운로드 가능.
주요 클라우드 파트너사를 통해서도 곧 제공될 예정.
WhatsApp, Messenger, Instagram Direct 및 Meta.AI 웹사이트에서 Llama 4 기반의 Meta AI 기능을 체험 가능.
결론:
Llama 4 시리즈는 더욱 강력하고 효율적인 멀티모달 AI 시대를 열었으며, 개발자들이 개인화된 경험을 구축할 수 있도록 지원하는 것을 목표로 합니다. Meta는 개방형 접근 방식을 통해 AI 혁신을 지속할 것입니다.