
** 영문공식블로그 번역본입니다. 오역이 있을수 있습니다.
Windows ML: Windows AI Foundry의 기반이 되는 성능이 뛰어난 온디바이스 추론을 위한 최첨단 런타임
머신 러닝은 기술 혁신의 선두에 서 있으며, 혁신적인 사용자 경험을 가능하게 합니다. 클라이언트 실리콘의 발전과 모델 소형화에 따라, 새로운 시나리오를 완전히 로컬에서 실행하는 것이 가능해졌습니다.
점점 더 복잡해지는 AI 환경에서 실제 서비스 경험을 제공하는 개발자들을 지원하기 위해, 저희는 성능이 뛰어난 온디바이스 모델 추론 및 배포 간소화에 최적화된 최첨단 런타임이자 Windows AI Foundry의 기반인 Windows ML의 공개 미리 보기를 발표하게 되어 매우 기쁩니다.
Windows ML은 개발자가 AI 기능이 통합된 애플리케이션을 쉽게 만들 수 있도록 설계되었습니다. 보급형 노트북, Copilot+ PC, 최고급 AI 워크스테이션 등 Windows의 다양한 하드웨어 생태계가 가진 놀라운 강점을 활용할 수 있습니다. 이것은 개발자가 어떤 디바이스에서든 특정 워크로드에 가장 적합한 클라이언트 실리콘을 활용할 수 있도록 돕기 위해 구축되었습니다. 저전력 및 지속적인 추론을 위한 NPU든, 강력한 성능을 위한 GPU든, 가장 넓은 범위와 유연성을 위한 CPU든 상관없이 말입니다.
Windows ML은 통합 프레임워크를 제공하므로 개발자는 현재 사용 가능한 Windows 11 PC를 자신 있게 타겟팅할 수 있습니다. 이것은 모델 성능 및 민첩성을 최적화하고 스택의 모든 계층에서 모델 아키텍처, 연산자 및 최적화의 혁신 속도에 대응하기 위해 처음부터 구축되었습니다. Windows ML은 지난 해 저희가 DirectML(DML)에서 얻은 학습 내용과 많은 개발자, 실리콘 파트너, 그리고 Copilot+ PC용 AI 경험을 개발하는 저희 팀의 피드백을 수렴하여 발전한 것입니다. Windows ML은 이러한 피드백을 염두에 두고 설계되었으며, 파트너사(AMD, Intel, NVIDIA, Qualcomm)가 실행 공급자 계약을 활용하여 모델 성능을 최적화하고 혁신 속도에 발맞출 수 있도록 지원합니다.
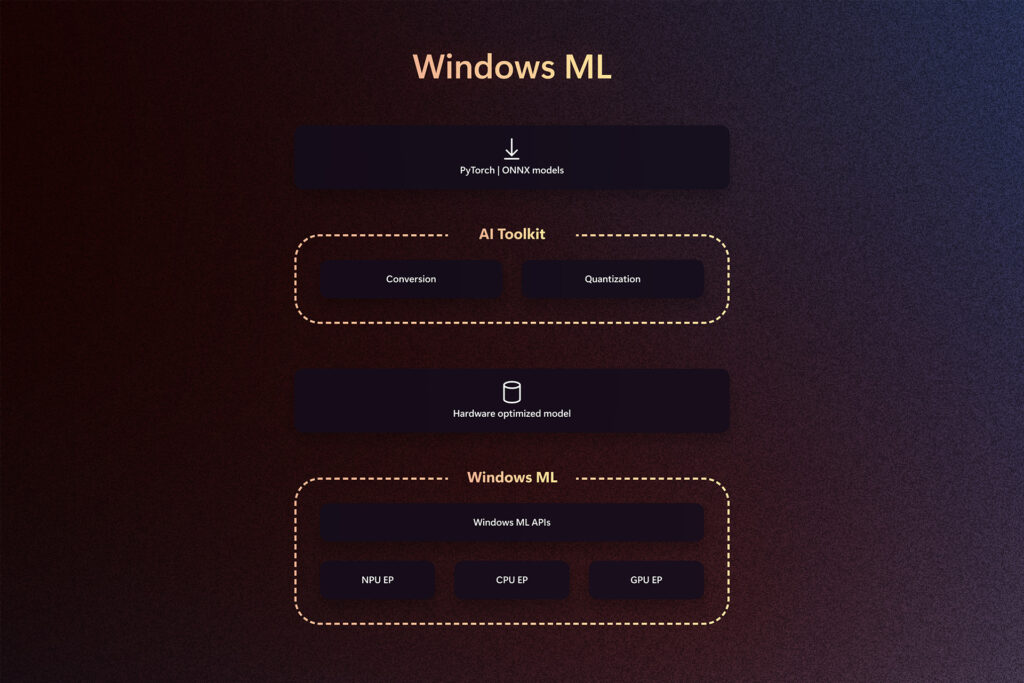
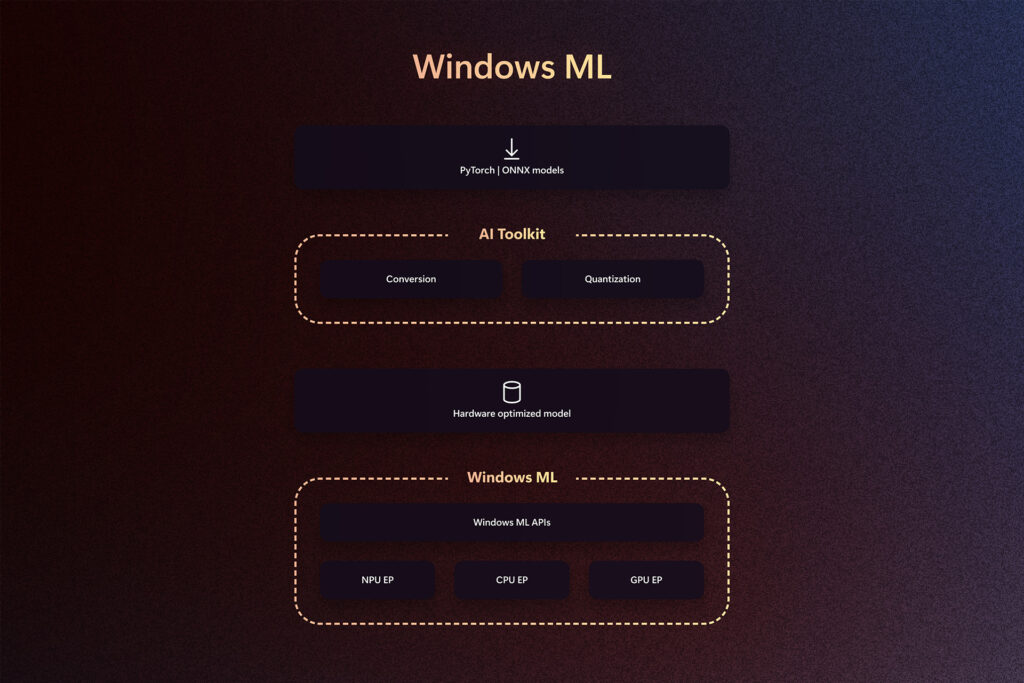
Windows ML은 ONNX Runtime Engine(ORT)을 기반으로 하며, 개발자가 익숙한 ORT API를 활용할 수 있도록 합니다. ONNX를 네이티브 모델 형식으로 사용하고 EP를 위한 PyTorch 중간 표현을 지원함으로써, Windows ML은 기존 모델 및 워크플로우와의 원활한 통합을 보장합니다. 주요 설계 측면 중 하나는 기존 ONNX Runtime 실행 공급자(EP) 계약을 활용하고 개선하여 다양한 클라이언트 실리콘에 대한 워크로드를 최적화하는 것입니다. 독립 하드웨어 벤더(IHV)와의 파트너십을 통해 구축된 이러한 실행 공급자는 기존 및 신흥 AI 프로세서에서의 모델 실행을 최적화하고, 각 프로세서가 최대 역량을 발휘하도록 설계되었습니다. 저희는 AMD, Intel, NVIDIA, Qualcomm과 긴밀히 협력하여 Windows ML에 그들의 EP를 원활하게 통합해 왔으며, 출시 시점부터 전체 CPU, GPU, NPU를 지원하게 되어 기쁘게 생각합니다.
AMD는 Ryzen AI 제품군에 대해 Windows ML을 전폭적으로 지원하며, AMD GPU 및 AMD NPU 실행 공급자를 통해 플랫폼의 GPU와 NPU를 최대한 활용할 수 있습니다. [자세히 알아보기].
“Windows ML은 CPU, GPU, NPU 전반에 걸쳐 원활하게 통합되어 Ryzen AI 300 시리즈를 포함한 AMD 포트폴리오 전반에서 ISV가 획기적인 AI 경험을 제공할 수 있도록 지원합니다. 마이크로소프트와 AMD 간의 긴밀한 파트너십은 Windows 상의 AI 미래를 이끌고 있으며, 성능, 효율성, 혁신 가속화를 최적화하고 있습니다.”
— John Rayfield, AMD AI 부문 부사장
Intel은 OpenVINO의 성능과 효율성을 Windows ML이 제공하는 개발 및 배포의 간결함과 함께 CPU, GPU, NPU 전반에 통합하여, AI 개발자가 Intel Core Ultra 프로세서로 구동되는 다양한 제품군에서 워크로드에 가장 적합한 XPU를 더 쉽게 타겟팅할 수 있도록 합니다. [자세히 알아보기].
“Windows ML에 대한 Intel과 마이크로소프트의 파트너십은 고성능, 고정밀 워크플로우를 Windows 생태계에 긴밀하게 통합하여 AI 앱 개발을 크게 향상시킵니다. CPU, GPU, NPU 중 무엇을 타겟팅하든, 개발자는 어떤 XPU에든 유연하게 배포할 수 있습니다. Intel과 OpenVINO 통합을 통해 초점은 기반 작업에서 발전으로 옮겨가며, 전 세계 Windows 사용자를 위해 더 빠르고 스마트한 AI 기반 앱을 구현합니다.”
— Sudhir Tonse Udupa, Intel AI PC 소프트웨어 엔지니어링 부문 부사장
NVIDIA의 새로운 TensorRT EP는 1억 대 이상의 RTX AI PC에서 NVIDIA RTX GPU 상의 AI 모델을 가장 빠르게 실행하는 방법입니다. 이전 Direct ML 구현과 비교했을 때, RTX용 TensorRT는 AI 워크로드 성능을 최대 2배 향상시킵니다. [자세히 알아보기].
“오늘날 Windows 개발자는 AI 워크로드에 대해 광범위한 하드웨어 호환성과 최대 성능 사이에서 선택해야 하는 경우가 많습니다. Windows ML을 통해 개발자는 광범위한 하드웨어를 쉽게 지원하는 동시에 NVIDIA GeForce RTX 및 RTX PRO GPU에서 최대 TensorRT 가속을 달성할 수 있습니다.”
— Jason Paul, NVIDIA 소비자 AI 부문 부사장
**Qualcomm Technologies Inc.**와 마이크로소프트는 Qualcomm Neural Network Execution Provider (QNN EP)를 사용하여 Snapdragon X Series 프로세서에 내장된 NPU용 Windows ML 기반 AI 모델 및 애플리케이션을 개발 및 최적화하기 위해 협력했습니다. [자세히 알아보기].
“새로운 Windows ML의 최첨단 런타임은 온디바이스 모델 추론을 최적화할 뿐만 아니라 배포를 간소화하여 개발자가 Snapdragon X Series 플랫폼의 고급 AI 프로세서 잠재력을 최대한 활용하기 더 쉽게 만듭니다. Windows ML의 통합 프레임워크와 NPU, GPU, CPU를 포함한 다양한 하드웨어 지원 덕분에 개발자는 광범위한 디바이스에서 뛰어난 성능과 효율성을 제공하는 AI 애플리케이션을 만들 수 있습니다. 저희는 마이크로소프트와의 지속적인 협력을 통해 혁신과 개발 속도를 가속화하여 Windows Copilot+ 플랫폼에서 최고의 AI 경험을 제공할 수 있기를 기대합니다.”
— Upendra Kulkarni, Qualcomm Technologies, Inc. 제품 관리 부문 부사장
Windows ML에 대해 강조할 몇 가지 주요 측면이 있습니다:
-
배포 간소화: 저희의 인프라 API를 활용함으로써, 개발자는 ONNX 또는 실행 공급자를 애플리케이션에 직접 번들링할 필요 없이 다양한 실리콘을 타겟팅하기 위해 여러 앱 빌드를 생성할 필요가 없어졌습니다. 저희는 이를 디바이스에서 사용 가능하도록 만들고, 간단한 등록 방법과 온디바이스 사전(AOT) 모델 컴파일 기능을 제공할 것입니다.
-
고급 실리콘 타겟팅: 디바이스 정책을 활용하여 저전력 또는 고성능에 최적화하거나, 특정 모델에 사용할 실리콘을 정확히 지정하도록 재정의할 수 있습니다. 향후에는 이를 통해 최적 성능을 위한 분할 처리(모델의 일부는 CPU나 GPU를 사용하고 다른 일부는 NPU를 사용하는 방식)가 가능해질 것입니다.
-
성능: Windows ML은 성능을 위해 설계되었습니다. ONNX와 ONNX Runtime 기반 위에 구축되어 다른 모델 형식 대비 최대 20% 개선된 성능을 보여줍니다. 시간이 지남에 따라 점진적 메모리 매핑, 부분 모델 고정, 병렬 실행을 위한 최적화된 스케줄러 등 Windows별 기능을 추가하여 추가 최적화를 할 것입니다.
-
호환성: 저희 IHV 파트너와 협력하여 Windows ML은 적합성 및 호환성을 보장하므로, 모델의 빌드 간 정확성을 보장하면서도 지속적인 개선을 신뢰할 수 있습니다.
하지만 이것은 런타임에 관한 것만이 아닙니다. 저희는 모델 및 앱 준비(PyTorch에서 ONNX로의 변환, 양자화, 최적화, 컴파일 및 프로파일링)를 지원하는 강력한 도구 세트를 VS Code용 AI 툴킷(AI 툴킷)에 도입하여 개발자가 독점 또는 오픈소스 모델을 사용해 상용 애플리케이션을 출시할 수 있도록 돕고 있습니다. 이 도구는 여러 빌드 및 복잡한 로직 생성 없이도 Windows ML을 통해 성능이 뛰어난 모델을 준비하고 출시하는 프로세스를 간소화하기 위해 특별히 설계되었습니다.
Windows ML은 오늘부터 전 세계 모든 Windows 11 머신에서 공개 미리 보기로 제공되어, 개발자들에게 기능을 탐색하고 피드백을 제공할 기회를 제공합니다. 미리 보기에는 두 가지 API 레이어가 포함됩니다:
-
ML 레이어: 런타임 초기화, 종속성 관리, 생성형 AI 루프 구축을 위한 도우미 API 등 고수준 API.
-
런타임 레이어: 온디바이스 추론의 세밀한 제어를 위한 저수준 ONNX Runtime API.
시작하려면 AI 툴킷을 설치하고, 저희 변환 및 최적화 템플릿 중 하나를 활용하거나 직접 구축을 시작하세요. Microsoft Learn에서 제공되는 문서 및 코드 샘플을 탐색하고, AI Dev Gallery(설치, 문서)에서 데모 및 추가 샘플을 확인하여 Windows ML을 시작하는 데 도움을 받으세요.

Windows ML을 구축하는 동안, 특히 AI 기반 기능 및 경험 제공의 선두에 있는 앱 개발자들로부터 피드백과 관점을 받는 것이 저희에게 중요했습니다. 저희는 Windows ML의 초기 미리 보기를 몇몇 선도적인 개발자들과 공유하여 통합 테스트를 진행했으며, 그들의 초기 반응에 매우 만족하고 있습니다:
개발자 사용 후기
Adobe (Volker Rölke – 선임 ML 컴퓨터 과학자): “Adobe Premiere Pro와 After Effects는 테라바이트 단위의 영상과 대규모 ML 워크로드를 처리합니다. 이기종 디바이스 전반에서 일관된 성능을 제공하는 신뢰할 수 있는 Windows ML API는 거대한 장애물을 제거하고 더 뛰어난 기능을 더 빠르게 출시할 수 있게 해 줄 것입니다. Windows ML은 훨씬 적은 상투적인 시스템 확인 및 저수준 의사 결정으로 하드웨어에 구애받지 않는 접근 방식을 취하는 데 도움이 될 수 있습니다.”
Bufferzone (Dr. Ran Dubin, Bufferzone CTO): “Bufferzone에서는 AI 기반 PC가 엔드포인트의 미래를 대표한다고 믿습니다. Windows ML은 ISV의 통합 문제를 간소화하고, 출시 기간을 단축하며, 더 높은 채택률을 촉진합니다. 결과적으로 고객은 PC에서 훨씬 더 많은 이점을 얻게 될 것이며, 이는 모두에게 엄청난 이점입니다.”
Filmora (Luyan Zhang – AI 제품 관리자): “간결함이 놀랍습니다. Microsoft의 더 쉬운 접근 방식에 따라 ONNX 모델을 저희 앱에 추가했습니다. 복잡한 AI 기능을 불과 3일 만에 Windows ML로 변환했습니다.”
McAfee (Carl Woodward, 선임 수석 엔지니어): “McAfee+의 새로운 스캠 탐지 기능의 개발 및 관리에 Windows ML이 가져올 수 있는 효율성에 대해 기대하고 있습니다. Windows ML은 모델 정확성 및 성능과 같이 영향력 높은 영역에 집중할 수 있게 해 줄 것이며, 새로운 하드웨어 개정판을 포함한 전체 생태계에서 AI 구성 요소가 잘 작동한다는 확신을 제공할 것입니다.”
Powder (Barthélémy Kiss – Powder 공동 설립자 겸 CEO): “Powder는 Windows ML의 초기 도입자이며, 이를 통해 모델 통합을 3배 더 빠르게 할 수 있었고, 속도를 핵심 전략적 이점으로 전환했습니다. Windows 11이 실리콘 제공업체 전반에서 힘든 작업을 처리함에 따라, 이제 저희 Powder 개발자들이 가장 잘하는 일, 즉 더 마법 같은 AI 비디오 경험을 더 짧은 시간 안에 훨씬 낮은 운영 비용으로 개발하는 데 더 집중할 수 있습니다.”
Reincubate (Aidan Fitzpatrick – Reincubate CEO): “저희는 첫 날부터 새로운 AI 하드웨어 칩셋을 지원하고 최대한 활용하는 데 전념하고 있습니다. 그리고 Windows ML은 저희가 실리콘 혁신 속도로 나아가는 데 도움이 되는 강력한 도구가 되어야 합니다. 저희에게 있어 궁극적인 목표는 단일 고정밀 모델을 가져와 Windows 실리콘 전반에서 원활하게 작동하게 하는 것이며, Windows ML이 올바른 방향으로 나아가는 중요한 단계라고 생각합니다.”
Topaz Labs (Dr. Suraj Raghuraman – AI 엔진 책임자): “Windows ML은 저희 설치 프로그램 크기를 기가바이트에서 메가바이트로 엄청나게 줄일 것입니다. 이를 통해 모델 저장 공간 요구 사항도 줄어들기 때문에 사용자는 디스크에서 더 많은 작업을 할 수 있습니다. Windows ML은 ONNX 런타임에 크게 의존하기 때문에 저희가 통합하기 정말 쉬웠습니다. 저희는 며칠 안에 전체 API를 통합했으며, 혁신 관점에서 원활한 경험이었습니다.”
숙련된 AI 개발자이든 ML을 처음 접하는 분이든 관계없이, Windows ML은 인프라 관리 대신 혁신에 집중할 수 있도록 지원하며, 앱 설치 공간을 줄이면서도 AI 기능이 통합된 애플리케이션으로 고객을 만족시킬 수 있도록 합니다. Windows ML은 올해 하반기에 정식 출시될 예정입니다. 그동안 저희는 여러분의 피드백과 Windows ML을 활용하여 가능성을 재정의하는 솔루션을 어떻게 만들어낼지 기대하고 있습니다. 오늘 Windows ML 여정에 참여하고 차세대 AI 혁신에 동참하세요!
편집자 주 - 2025년 5월 19일 - ONNX Runtime Engine 기반 Windows ML에 대한 위 섹션이 추가 정보를 제공하기 위해 업데이트되었습니다.
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

 8코어 AMD 라이젠 AI 맥스 프로 38...
8코어 AMD 라이젠 AI 맥스 프로 38...
 MSI의 "실수 방지용" 노란색...
MSI의 "실수 방지용" 노란색...
















{kind=link}
{kind=link}
{kind=link}