

**번역본뉴스입니다. 오역이 있을수 있습니다.
High Yield 유튜브 채널에 따르면, AMD는 기존의 SERDES 기반 다이‑투‑다이 링크를 포기하고 팬아웃 및 RDL(재배선 레이어) 패키징을 통해 넓은 평행 “Sea‑of‑Wires” 배선을 도입하려는 것으로 알려졌습니다.

이러한 변화의 첫 번째 단서는 Strix Halo APU 사진에서 확인할 수 있습니다. 샘플에는 팬아웃이 위치할 것으로 예상되는 사각형 패드 영역이 보이며, 이전에 CCD(칩‑클러스터‑다이) 가장자리에 있던 대형 SERDES 블록은 눈에 띄게 사라졌습니다. 이 패턴과 TSMC의 InFO‑oS와 일치하는 패키징 선택을 종합하면, AMD가 고속 직렬 링크 몇 개로 집중되던 데이터를 다수의 밀집 평행 트레이스로 전환하려는 시도임을 알 수 있습니다. 기존 방식에서는 패키지 경계마다 직렬화·역직렬화를 수행해야 하는데, 이는 클럭 복구, 이퀄라이제이션, 인코딩·디코딩 오버헤드로 인해 전력 소모와 지연이 추가됩니다.

다수의 짧은 평행 와이어로 전환함으로써 AMD는 반복적인 PHY 작업을 없애고 왕복 지연 시간을 감소시킬 수 있으며, 물리적 라인을 추가함으로써 순수 대역폭을 확장할 수 있습니다. 또한, 기존에 큰 SERDES 블록이 차지하던 면적을 해방시켜 CCD, 메모리 컨트롤러 및 가속기들을 더 가까이 배치하고 통신 비용을 낮출 수 있습니다.
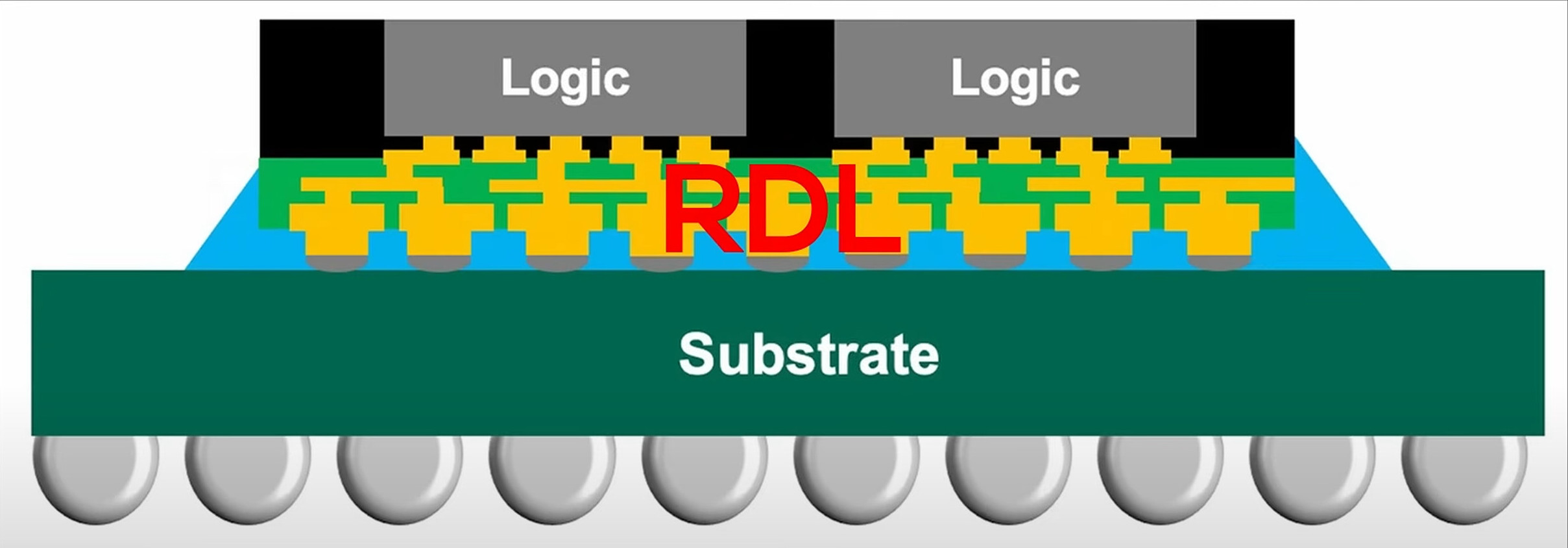
하지만 해결해야 할 실질적인 트레이드오프도 존재합니다. 다이 아래에 많은 평행 트레이스를 배치하면 신호 무결성, 열 관리, 라우팅 및 제조 측면에서 어려움이 발생하므로 다층 RDL 설계와 다이·패키지 팀 간 긴밀한 공동 엔지니어링이 필수적입니다. AMD가 이러한 문제들을 해결하고 이 방식을 Zen 6에 적용한다면, CPU 워크로드에서 와트당 성능 및 지연 시간 개선을 기대할 수 있습니다. 특히 I/O 다이의 지연 감소 덕분에 메모리 IMC(인터페이스 메모리 컨트롤러)의 속도가 빨라지는 효과도 기대됩니다.
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

 ECS Z11 Plus 미니 PC 시리즈가 In...
ECS Z11 Plus 미니 PC 시리즈가 In...
 Intel “Granite Rapids‑WS”가 86코...
Intel “Granite Rapids‑WS”가 86코...


















{kind=link}
{kind=link}
{kind=link}
{kind=link}