
**Thinking Machines Lab 게시물 번역본입니다. 오역이 있을수 있습니다.
**인터렉션이미지가 있습니다. 전부다 옮기지 못했습니다. 자세한사항은 홈페이지를 참조해주세요
오늘, 저희는 외부 스캐폴딩(scaffolding)을 통해서가 아니라 상호작용을 기본적으로(natively) 처리하는 모델인 '상호작용 모델(interaction models)'의 연구 프리뷰를 발표합니다. 저희는 상호작용성이 지능과 함께 확장되어야 한다고 생각합니다. 우리가 AI와 함께 일하는 방식을 나중에 덧붙이는 부수적인 것으로 취급해서는 안 됩니다. 상호작용 모델은 우리가 다른 사람들과 자연스럽게 협력하는 방식과 동일하게 사람들이 AI와 협력할 수 있게 해줍니다. 이 모델은 오디오, 비디오 및 텍스트를 지속적으로 받아들이고 실시간으로 생각하며, 응답하고, 행동합니다.
협업의 병목 현상 (The collaboration bottleneck)
AI 연구소들은 종종 AI가 자율적으로 작업하는 능력을 모델의 가장 중요한 기능으로 취급합니다. 그 결과, 오늘날의 모델과 인터페이스는 인간이 루프(loop, 작업 과정)에 계속 참여하도록 최적화되어 있지 않습니다.
자율형 인터페이스는 가치가 있지만, 대부분의 실제 업무에서 사용자는 자신의 요구 사항을 사전에 완벽하게 명시하고 자리를 비울 수 없습니다. 좋은 결과는 인간이 과정에 계속 참여하면서 명확히 설명하고 피드백을 제공하는 협업 과정에서 나옵니다. 하지만 점점 더 인간이 배제되는 이유는 작업에 인간이 필요 없어서가 아니라 인터페이스에 인간이 개입할 여지가 없기 때문입니다. 대신, 사람들은 우리가 다른 사람들과 협력할 때처럼 메시지를 주고받고, 말하고, 듣고, 보고, 보여주고, 필요할 때 끼어드는 방식으로 AI와 협력할 수 있을 때 가장 효과적입니다. 그리고 모델 역시 동일하게 행동해야 합니다.
이를 해결하기 위해서는 모델을 위한 현재의 턴(turn) 기반 인터페이스를 넘어서야 합니다. 오늘날의 모델은 현실을 단일 스레드(thread)로 경험합니다. 사용자가 타이핑이나 말을 마칠 때까지 모델은 사용자가 무엇을 하고 있는지, 어떻게 하고 있는지 전혀 인식하지 못한 채 기다립니다. 모델이 생성을 마칠 때까지 모델의 인식은 정지되며, 생성이 끝나거나 중단될 때까지 어떠한 새로운 정보도 받지 못합니다. 이는 인간-AI 협업에 있어 좁은 채널을 만들어 내며, 사람의 지식, 의도, 판단이 모델에 얼마나 도달할 수 있는지, 그리고 모델의 작업을 얼마나 이해할 수 있는지를 제한합니다. 중요한 의견 충돌을 직접 만나서가 아니라 이메일로 해결하려 한다고 상상해 보십시오.
저희 씽킹 머신스는 어떠한 모달리티(modality)에서도 AI가 실시간으로 상호작용할 수 있도록 함으로써 이러한 대역폭 병목 현상을 해결할 수 있다고 믿습니다. 이를 통해 인간이 AI 인터페이스에 억지로 맞추도록 강요하는 대신, AI 인터페이스가 인간이 있는 그곳으로 다가갈 수 있게 됩니다.
대부분의 기존 AI 모델은 하네스(harness, 연결 장치)를 사용하여 상호작용성을 덧붙입니다. 즉, 구성 요소들을 꿰매어 끼어들기, 다중 모달리티 또는 동시성을 모방합니다. 그러나 "쓴 교훈(the bitter lesson)"이 시사하듯, 이렇게 수작업으로 만든 시스템은 일반적인 기능의 발전에 뒤처지게 될 것입니다. 상호작용성이 지능과 함께 확장되려면 상호작용성이 모델 자체의 일부가 되어야 합니다. 이 접근 방식을 사용하면, 모델을 확장할 때 모델은 더 똑똑해지고 더 나은 협력자가 됩니다.
기능 (Capabilities)
상호작용성이 모델의 일부가 되면, 그렇지 않았다면 하네스에 구현해야만 했을 다양한 기능들이 가능해집니다.
더 긴 실제 세션에서는 이 모든 것이 지속적으로 발생하여 프롬프팅(prompting)보다는 협업하는 듯한 느낌을 주는 경험을 만들어냅니다.
(이 비디오에 등장하는 브랜드나 제품은 Thinking Machines Labs와 아무런 관련이 없습니다. 이 비디오는 모델의 기능을 시연하기 위한 것이며 후원이나 파트너십을 나타내지 않습니다.)
우리의 접근 방식 (Our approach)
턴 기반 (Turn based) 입력과 출력은 순서가 있는 하나의 토큰 시퀀스로 평탄화됩니다.
입력 1 -> 인간 -> 출력 1 -> 모델 -> 입력 2 -> 출력 2 -> 입력 3 -> 출력 3
시간에 맞춰 정렬된 마이크로-턴 기반 (Time-aligned micro-turn based)
상호작용은 연속적인 입력 및 출력 스트림이 마이크로-턴으로 분할되어 시간에 기반을 둡니다. (모델이 즉시 끼어들어 응답합니다. / 모델과 사용자가 모두 침묵을 유지합니다. / 사용자가 말하는 동안 모델이 맞장구를 칩니다. / 명시적인 프롬프트 없이도 모델이 시각적 단서에 반응합니다.)
턴 기반 모델은 교대로 나타나는 토큰 시퀀스를 봅니다. 시간을 인식하는 상호작용 모델은 마이크로-턴의 연속적인 스트림을 보므로 침묵, 겹침, 끼어들기가 모델 문맥의 일부로 유지됩니다.
상호작용 모델은 사용자와 지속적으로 양방향 교환을 하며, 인식과 응답을 동시에 수행합니다. 일부 분야에서는 이러한 상호작용성을 당연한 것으로 여깁니다. 물리적 세계는 로봇 공학과 자율 주행 차량이 실시간으로 작동할 것을 요구합니다. 오디오 풀 듀플렉스(full-duplex) 모델은 상호작용이 양방향이고 연속적인 또 다른 예입니다.
동일한 원리를 적용하여, 저희는 이 체제에 기본적으로 맞춰진 상호작용 모델을 구축하기 시작했습니다. 즉, 오디오, 비디오, 텍스트 전반에 걸쳐 동일한 연속 루프 안에서 인식하고 응답하는 모델입니다. 그 결과 두 가지 아이디어를 중심으로 설계된 시스템이 탄생했습니다. 바로 실시간 존재감을 유지하는 '시간 인식 상호작용 모델'과 지속적인 추론, 도구 사용, 장기적인 작업을 처리하는 '비동기식 백그라운드 모델'입니다.
시스템 개요 (System overview)
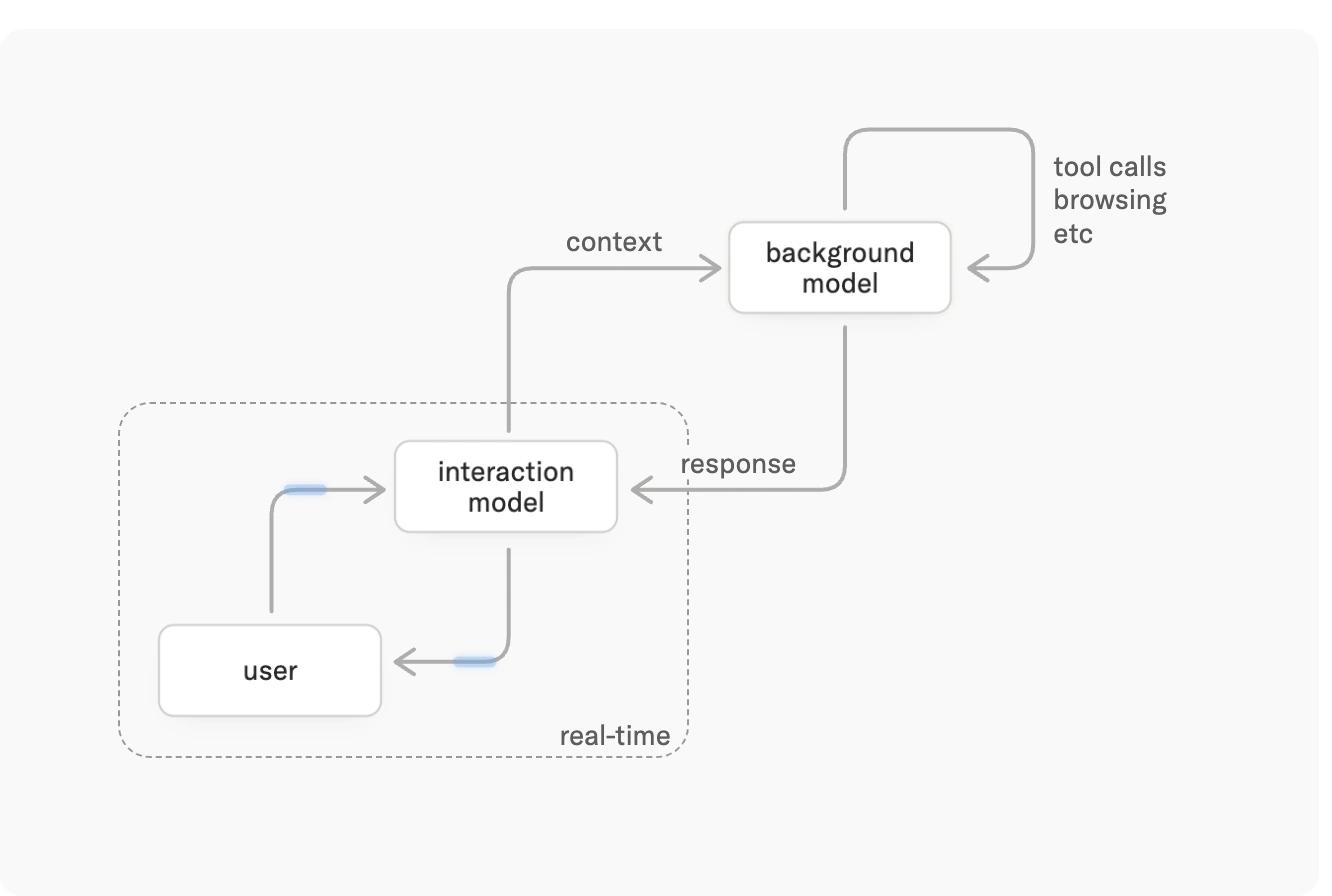
상호작용 모델은 사용자와 끊임없이 교류합니다. 즉각적으로 생성할 수 있는 것보다 더 깊은 추론이 필요한 작업의 경우, 상호작용 모델은 비동기적으로 실행되는 백그라운드 모델에 이를 위임합니다. 상호작용 모델은 후속 질문에 답하고, 새로운 입력을 받고, 대화의 맥락을 유지하는 등 전체 과정에서 계속 존재하며, 백그라운드 모델의 결과가 도착하는 대로 대화에 통합합니다.
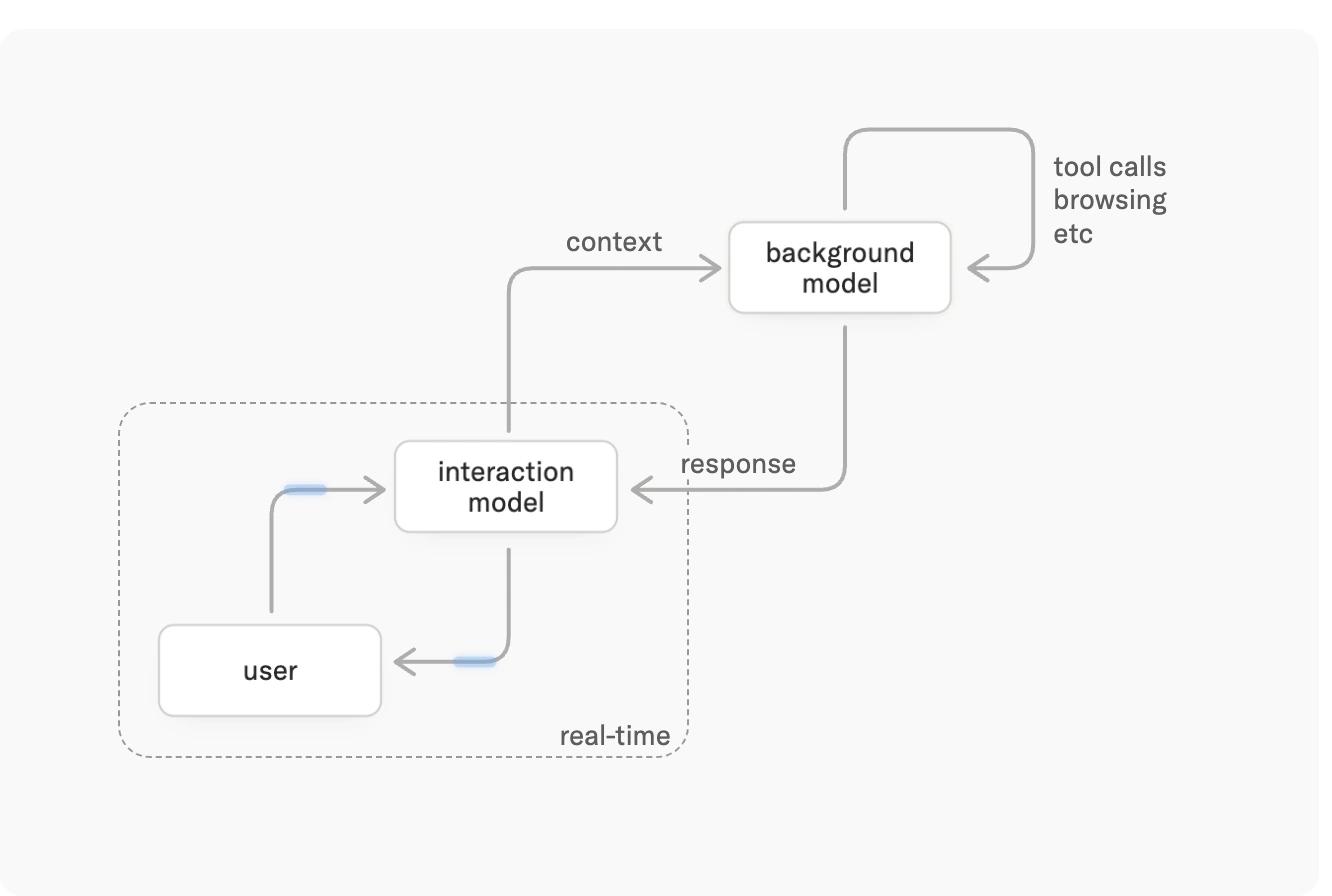
(사용자는 상호작용 모델과 지속적으로 상호작용하는 한편, 백그라운드 모델은 비동기 작업을 수행합니다. 두 시스템은 서로의 문맥을 공유합니다.)
이러한 분리를 통해 사용자는 생각하지 않는 모델 수준의 응답 지연 시간(latency)으로 추론 모델의 계획, 도구 사용, 에이전트 워크플로우 등 지능의 모든 범위뿐만 아니라 반응성의 이점을 모두 누릴 수 있습니다. 백그라운드 모델과 상호작용 모델 모두 지능적이라는 점에 유의하십시오. 상호작용 모델 자체만으로도 상호작용성 및 지능 벤치마크 모두에서 경쟁력이 있습니다.
상호작용 모델 (The interaction model)
저희의 출발점은 본질적으로 실시간인 모달리티인 연속 오디오 및 비디오입니다. 텍스트는 기다릴 수 있지만, 라이브 대화는 그럴 수 없습니다. 가장 어려운 사례를 먼저 중심으로 설계함으로써, 저희는 기본적으로 다중 모달리티를 지원하고 시간을 인식하며 모든 모달리티에 걸쳐 동시 입력 및 출력 스트림을 처리할 수 있는 아키텍처에 도달했습니다. 몇 가지 설계상의 선택이 이를 가능하게 했습니다.
시간에 맞춰 정렬된 마이크로-턴 (Time-aligned micro-turns): 상호작용 모델은 200ms 분량의 입력 처리와 200ms 분량의 출력 생성을 지속적으로 교차(interleave)하는 마이크로-턴으로 작동합니다. 완전한 사용자 턴을 소비하고 완전한 응답을 생성하는 대신, 입력 및 출력 토큰 모두 스트림으로 처리됩니다. 이러한 스트림의 200ms 청크(chunk) 단위로 작업하면 다중 입력 및 출력 모달리티의 거의 실시간에 가까운 동시성이 가능해집니다.
(인간의 인식은 동시 입력 및 출력 스트림을 보존하는 반면, 모델은 단일하게 교차된 토큰 시퀀스를 받습니다.)
이 설계를 통해 모델이 준수해야 할 인위적인 턴 경계가 사라집니다. 대조적으로, 대부분의 기존 실시간 시스템은 턴 기반 모델이 실시간처럼 응답성이 있다고 느끼게 하기 위해 턴 경계를 예측하는 하네스를 필요로 합니다. 이 하네스는 모델 자체보다 지능이 현저히 떨어지는 음성 활동 감지(VAD)와 같은 구성 요소로 만들어집니다. 이는 선제적인 끼어들기("내가 틀린 말을 하면 끼어들어 줘")나 시각적 단서에 대한 반응("내 코드에 버그를 작성하면 말해 줘")과 같은 다양한 상호작용 모드를 불가능하게 만듭니다. 나아가, 이 모델은 들으면서 말하거나("스페인어를 영어로 실시간 번역해 줘") 보면서 말하는 것("이 스포츠 경기를 실시간으로 해설해 줘")과 같은 작업도 할 수 있습니다.
따라서 오늘날 특별한 하네스를 필요로 하는 이 모든 다양한 상호작용 모드는 모델이 할 수 있는 일의 특별한 사례가 되며, 모델 크기와 훈련 데이터를 확장함에 따라 품질이 향상됩니다.
인코더가 없는 조기 융합 (Encoder-free early fusion): 크고 독립적인 인코더를 통해 오디오와 비디오를 처리하는 대신, 저희는 사전 처리(pre-processing)를 최소화한 시스템을 선택했습니다. 많은 옴니모달 모델은 별도의 인코더나 디코더를 훈련해야 합니다. 저희는 그 대신 오디오 신호를 dMel로 받아들이고 이를 경량화된 임베딩 레이어를 통해 변환합니다. 이미지는 40x40 패치로 분할되어 hMLP에 의해 인코딩됩니다. 오디오 디코더의 경우 플로우 헤드(flow head)를 사용합니다. 모든 구성 요소는 트랜스포머와 함께 처음부터 공동 훈련됩니다.
(단일 200ms 마이크로-턴에 대한 상호작용 모델 아키텍처의 그림입니다. 모델은 텍스트, 오디오 또는 비디오의 모든 하위 집합을 받아들이고 텍스트와 오디오를 예측합니다.)
추론 최적화 (Inference optimization): 추론 시에는 200ms 청크가 작은 크기의 빈번한 프리필(prefill)과 디코드를 요구하며, 각각은 엄격한 지연 시간 제약을 충족해야 합니다. 안타깝게도 기존의 LLM 추론 라이브러리는 잦고 작은 프리필에 최적화되어 있지 않아 턴마다 상당한 오버헤드를 발생시킵니다. 이를 해결하기 위해 저희는 스트리밍 세션(streaming sessions)을 구현했습니다. 클라이언트는 각 200ms 청크를 개별 요청으로 보내고, 추론 서버는 GPU 메모리 내의 영구적인 시퀀스에 이 청크들을 추가합니다. 이는 빈번한 메모리 재할당 및 메타데이터 계산을 방지하며, 저희는 이 기능의 버전을 SGLang에 업스트림했습니다. 또한, 양방향 서빙에서 관찰되는 형태와 지연 시간을 위해 커널(kernels)을 최적화했습니다. 예를 들어, MoE 커널에 표준 그룹화된 gemm 대신 gather+gemv 전략을 사용합니다.
트레이너-샘플러 정렬 (Trainer-sampler alignment): 저희는 비트 단위(bitwise) 트레이너-샘플러 정렬이 시스템의 다양한 구성 요소를 디버깅하는 것뿐만 아니라 훈련 안정성에도 유용하다는 것을 발견했습니다. 엔드투엔드 성능 오버헤드가 최소화(<5%)된 배치 불변 커널을 구현했습니다. 두 가지 특정 커널을 강조하자면 다음과 같습니다.
-
All-reduce 및 reduce-scatter: 저희는 Blackwell에서 결정론적인 저지연 통신 커널을 구현하기 위해 NVLS를 사용하며, 다소 다른 병렬화 전략 간에 비트 단위 정렬을 달성합니다.
-
어텐션 (Attention): 어텐션의 주요 과제는 Split-KV인데, 이는 디코드와 프리필 간에 일관되지 않은 누적 순서를 초래할 수 있습니다. 그러나 디코드와 프리필 간에 일관되게 분할하도록 선택함으로써 일관된 누적 순서를 유지할 수 있습니다.
상호작용 모델과 백그라운드 모델 간의 조정: 상호작용 모델이 위임할 때, 독립적인 단일 쿼리가 아니라 전체 대화라는 풍부한 문맥 패키지를 보냅니다. 백그라운드 모델이 결과를 생성함에 따라 결과가 스트리밍되어 돌아오며, 상호작용 모델은 급격한 문맥 전환이 아니라 사용자가 현재 하고 있는 작업에 적절한 시점에 이러한 업데이트를 대화에 교차시킵니다.
안전성 (Safety): 실시간 상호작용은 턴 기반 교환과는 다르게 안전성에 부하를 주기 때문에, 저희의 안전 관련 작업은 모달리티에 적절한 거부와 장기적인 강건성이라는 두 가지 축에 집중했습니다. 발화 시 거부를 구어체로 만들기 위해 텍스트 음성 변환(TTS) 모델을 사용하여 허용되지 않는 다양한 주제를 다루는 훈련 데이터를 생성했으며, 자연스러운 표현이면서도 단호함은 잃지 않도록 조정했습니다. 연장된 음성 대 음성 대화 전반에 걸쳐 강건성을 향상시키기 위해 자동화된 레드팀(red-teaming) 하네스를 사용하여 다중 턴 거부 데이터를 생성했습니다.
벤치마크 (Benchmarks)
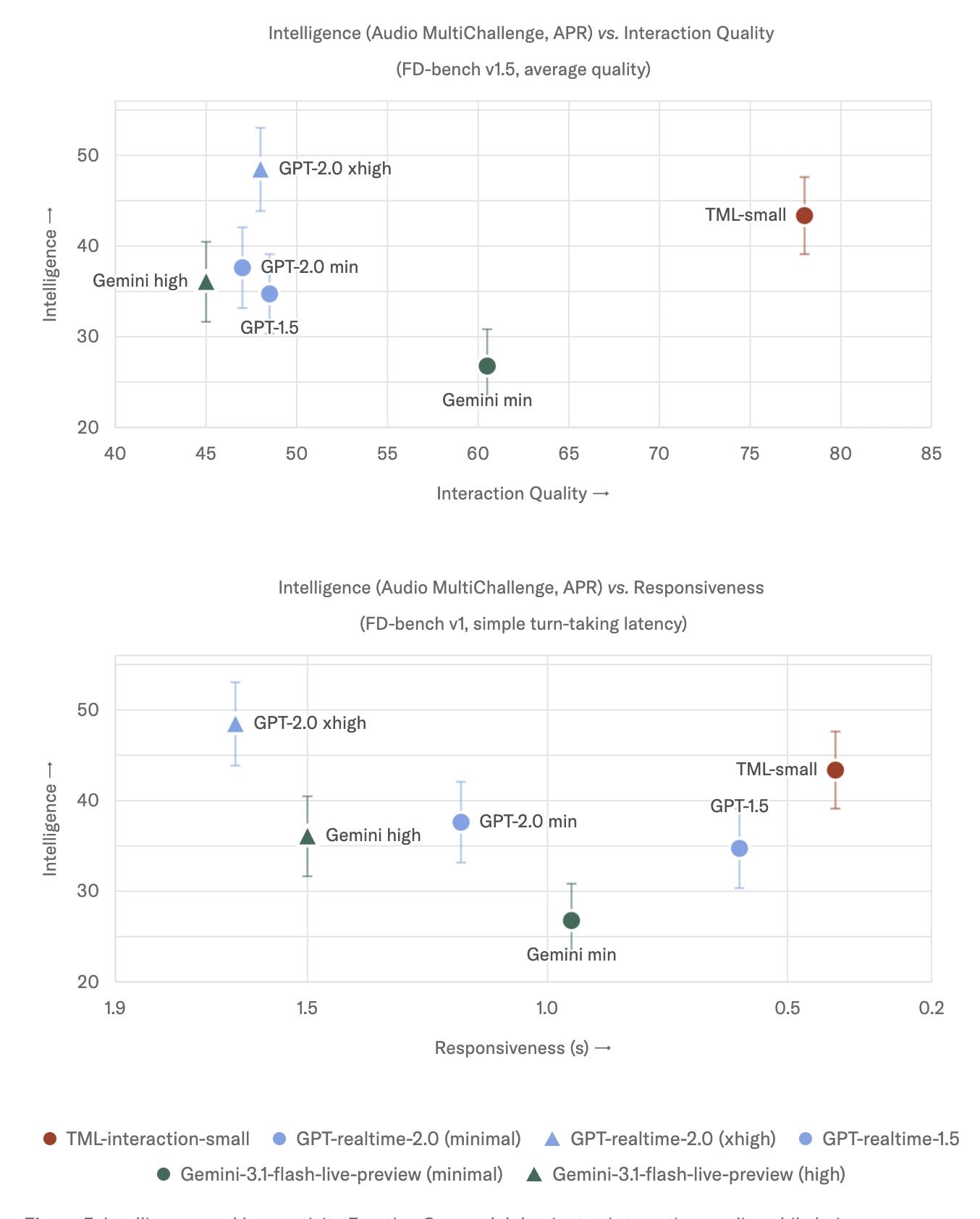
지능 및 상호작용성의 최전선 (Intelligence and interactivity frontier) 저희는 TML-Interaction-Small이라고 명명된 모델이 강력한 지능/명령어 따르기와 상호작용성을 모두 갖춘 최초의 모델임을 보여줍니다. 상호작용 품질을 측정하기 위해 고안된 몇 안 되는 벤치마크 중 하나인 FD-bench를 사용합니다. FD-bench v1.5에서는 모델에 미리 녹음된 오디오가 주어지며, 모델은 특정 시점에 응답해야 합니다. 저희 모델은 모든 영역에서 좋은 점수를 얻었습니다. 지능을 정량화하기 위해 Audio MultiChallenge를 사용합니다.
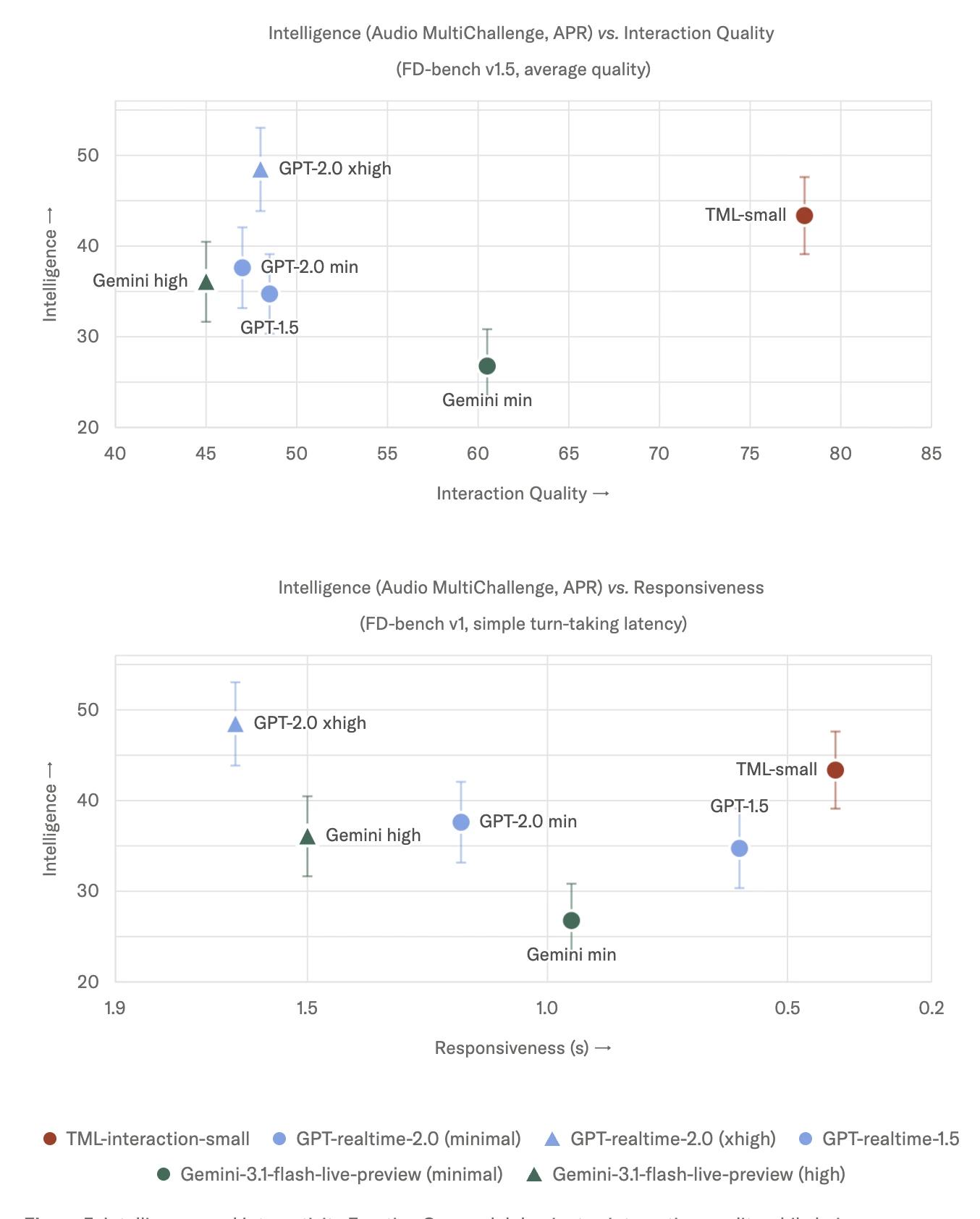
(지능과 상호작용성의 최전선. 저희 모델은 생각하지 않는 그 어떤 모델보다 똑똑하면서도 상호작용 품질을 압도합니다. 저희는 사용자와 모델의 턴 사이의 지연 시간으로 측정된 최고의 반응성을 달성했습니다.)
상호작용성의 새로운 차원 (New dimensions of interactivity)
기존의 상호작용성 지향 벤치마크들은 저희가 목격한 상호작용 기능의 질적인 도약을 적절히 포착하지 못합니다. 이를 위해, 저희는 이러한 기능들을 정량화하는 초기 연구를 진행했습니다.
시간 인식 및 동시 발화: 대화 관리 시스템이 있는 턴 기반 모델은 정확한 시간 추정이나 동시 발화를 지원하지 않습니다. 저희는 이러한 선제적인 오디오 기능을 측정하기 위해 두 가지 내부 벤치마크를 만들었습니다.
| Category | Metric · Modality | Instant | Thinking | |||||
|---|---|---|---|---|---|---|---|---|
| TML-interaction -small |
GPT-realtime-2.0 (minimal) |
GPT-realtime-1.5 | Gemini-3.1-flash-live (minimal) |
Qwen 3.5 OMNI-plus-realtime |
GPT-realtime-2.0 (xhigh) |
Gemini-3.1-flash-live (high) |
||
| Streaming | ||||||||
| FD-bench V1 | Turn-taking latency (s) · Audio | 0.40 | 1.18 | 0.59 | 0.57 | 2.14 | 1.63 | 0.94 |
| FD-bench V1.5 | Average · Audio | 77.8 | 46.8 | 48.3 | 54.3 | 39.0 | 47.8 | 45.5 |
| FD-bench V3 | Response Quality (%) / Pass@1 (%) · Audio + Tools |
82.8* / 68.0* | 80.0 / 52.0 | 77.9 / 55.0 | 68.5 / 48.0 | 60.0 / 50.0 | 81.0 / 58.0 | 71.4 / 48.0 |
| QIVD** | Accuracy (%) · Video + Audio | 54.0 | 57.5 | 41.2 | 54.7 | 59.0 | 58.2 | 56.1 |
| Turn-based | ||||||||
| Audio MultiChallenge | APR (%) · Audio | 43.4 | 37.6 | 34.7 | 26.8 | -*** | 48.5 | 36.1 |
| BigBench Audio | Accuracy (%) · Audio | 75.7 / 96.5* | 71.8 | 81.4 | 71.3 | 73.0 | 96.6**** | 96.6 |
| IFEval (VoiceBench) | Accuracy (%) · Audio | 82.1 | 81.7 | 68.1 | 67.6 | 80.3 | 83.2 | 82.8 |
| IFEval | Accuracy (%) · Text | 89.7 | 89.6 | 87.5 | 85.8 | 83.4 | 95.2 | 90.0 |
| Harmbench | Refusal rate (%) · Text | 99.0 | 99.5 | 100.0 | 99.0 | 99.5 | 100.0 | 98.0 |
-
TimeSpeak: 올바른 콘텐츠를 생성하면서 사용자가 지정한 시간에 모델이 발화를 시작할 수 있는지 테스트합니다.
-
CueSpeak: 의미적으로 올바른 예상 응답과 함께 모델이 적절한 순간에 말하는지 테스트합니다.
두 벤치마크 모두 LLM 심판으로 채점되며, 예상되는 의미를 전달하고 적절한 시기에 전달된 경우에만 올바른 것으로 간주됩니다.
시각적 선제성 (Visual proactivity): 오늘날의 상용 실시간 API는 시각적 세계가 변할 때 선제적으로 발언하도록 선택할 수 없습니다. 모델의 시각적 선제성을 평가하기 위해 세 가지 벤치마크를 채택했습니다.
-
RepCount-A: 비디오의 반복적인 행동 횟수를 세는 작업입니다. 지속적인 시각적 추적과 적시의 계산 능력을 측정합니다.
-
ProactiveVideoQA: 특정 순간에 대답을 알 수 있게 되는 질문이 포함된 비디오들로 구성됩니다. 정확한 시간에 정확한 답이 필요합니다.
-
Charades: 시간적 행동 국소화 벤치마크로, 지정된 시간 간격 동안 발생하는 동작을 파악합니다.
기존의 어떠한 모델도 이러한 작업을 의미 있게 수행할 수 없습니다. 평가된 모든 모델은 침묵을 유지하거나 오답을 제공합니다.
미래의 평가 (Future evals): 상호작용성이 향후 연구를 위한 중요한 분야라고 믿으며 커뮤니티가 벤치마크를 기여해 주기를 바랍니다. 상호작용 모델 및 인간-AI 협업 분야에 대한 연구 보조금을 출범하고 있습니다.
한계점 및 향후 과제 (Limitations and future work)
-
긴 세션: 지속적인 오디오와 비디오는 문맥을 빠르게 축적시킵니다. 매우 긴 세션은 여전히 세심한 문맥 관리가 필요합니다.
-
컴퓨팅 및 배포: 낮은 지연 시간으로 스트리밍하려면 신뢰할 수 있는 연결이 필요합니다. 지연된 프레임에 더욱 강건해지도록 모델을 훈련할 계획입니다.
-
정렬 및 안전성: 실시간 인터페이스의 안전성 연구를 위해 피드백을 수집하고 있습니다.
-
모델 크기 확장: 현재 모델은 276B 매개변수입니다. 올해 말에 더 큰 사전 훈련된 모델을 출시할 계획입니다.
-
개선된 백그라운드 에이전트: 백그라운드 에이전트가 상호작용 모델과 어떻게 협력할 수 있는지 지속적으로 탐구할 것입니다.
여러분의 생각을 들려주세요. 저희와 함께해 주십시오.
향후 몇 달 내에 피드백 수집을 위해 제한적인 연구 프리뷰를 오픈할 예정이며, 올해 말에 더 널리 공개할 계획입니다. 여러분이 저희와 함께해 주시기를 진심으로 바랍니다. interaction@thinkingmachines.ai 로 의견을 공유해 주십시오.
인용 (Citation) 이 연구를 다음과 같이 인용해 주십시오. Thinking Machines Lab, "상호작용 모델: 인간-AI 협력을 위한 확장 가능한 접근 방식", Thinking Machines Lab: Connectionism, 2026년 5월.
또는 BibTeX 인용을 사용해 주십시오.
@article{thinkingmachines2026interactionmodels,
author = {Thinking Machines Lab},
title = {Interaction Models: A Scalable Approach to Human-AI Collaboration},
journal = {Thinking Machines Lab: Connectionism},
year = {2026},
month = {May},
note = {https://thinkingmachines.ai/blog/interaction-models/},
doi = {10.64434/tml.20260511},
}
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

 에이수스(ASUS), 2.5슬롯 디자인의 Pro...
에이수스(ASUS), 2.5슬롯 디자인의 Pro...
 GEEKOM, AMD 라이젠 AI 9 HX 470...
GEEKOM, AMD 라이젠 AI 9 HX 470...

















{kind=link}
{kind=link}