

**번역본뉴스입니다. 오역이 있을수 있습니다.
AMD의 2025년 HEDT 및 프로 워크스테이션 라인업, 역대 가장 강력한 성능으로 등장
몇 주 전 컴퓨텍스 2025에서 AMD는 하이엔드 데스크톱(HEDT) 및 전문가용 워크스테이션 시장을 위한 최신 CPU와 GPU인 Ryzen 스레드리퍼 9000 및 Radeon AI Pro 9000 시리즈를 공개했습니다. 아마 아시다시피, AMD의 Ryzen 스레드리퍼 9000 시리즈와 새로운 Radeon AI Pro는 각각 Zen 5 및 RDNA 4 아키텍처를 기반으로 하며, 이 두 아키텍처는 이미 소비자 시장에 출시된 지 꽤 되었습니다. 따라서, 우리는 이미 이 제품들을 작동시키는 기술에 대해 매우 잘 알고 있습니다. 하지만 AMD의 Ryzen 스레드리퍼 9000 및 Radeon AI Pro 9000 시리즈는 각 제품 카테고리에서 새로운 길을 개척하며 현재까지 AMD의 가장 강력한 하이엔드 데스크톱 및 전문가용 워크스테이션 제품을 대표합니다.
우리는 이미 컴퓨텍스에서 나온 초기 발표 내용을 다루었고 Zen 5와 RDNA 4에 대한 심층 분석 기사도 몇 편 게재했으므로, 흥미로운 세부 정보를 알고 싶으시다면 읽어보실 자료가 있습니다. 하지만 오늘 공유할 새로운 제품 세부 정보와 성능 데이터가 있으니, 먼저 약간의 복습이 필요할 것 같습니다. 먼저, Ryzen 스레드리퍼 9000 시리즈에 대해 논의해 보겠습니다...

AMD Ryzen 스레드리퍼 9000 시리즈 소개
새로운 스레드리퍼 9000 시리즈는 증가된 데이터 처리량, 성능, 그리고 플랫폼 대역폭에 중점을 둡니다. 우리는 기존의 엔지니어링, 과학, 미디어 및 엔터테인먼트, 디자인 워크로드가 여전히 널리 퍼져 있는 전문가용 워크스테이션의 새로운 시대로 접어들고 있습니다. 그러나 새롭게 부상하는 AI 및 머신러닝 워크로드 또한 스레드리퍼 9000의 막대한 대역폭과 병렬 컴퓨팅 능력의 혜택을 받을 것입니다. 이를 염두에 둘 때, 스레드리퍼 9000은 엄청난 양의 컴퓨팅, 대역폭 및 IO로부터 상당한 이점을 얻을 새로운 세대의 워크스테이션에 동력을 공급할 좋은 위치에 있습니다. 이 플랫폼에서는 전체 PCIe 대역폭을 사용하는 쿼드 GPU 구성이 가능합니다.
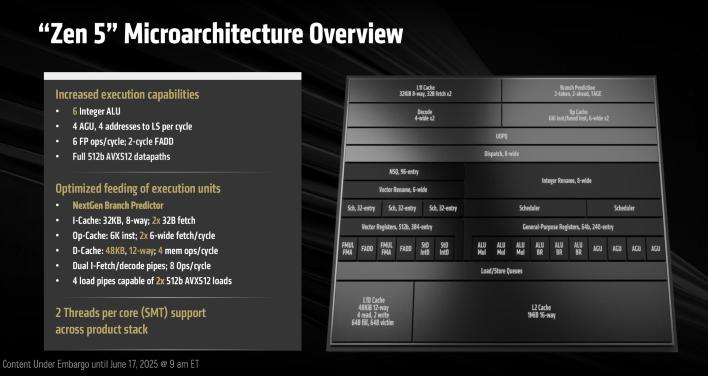
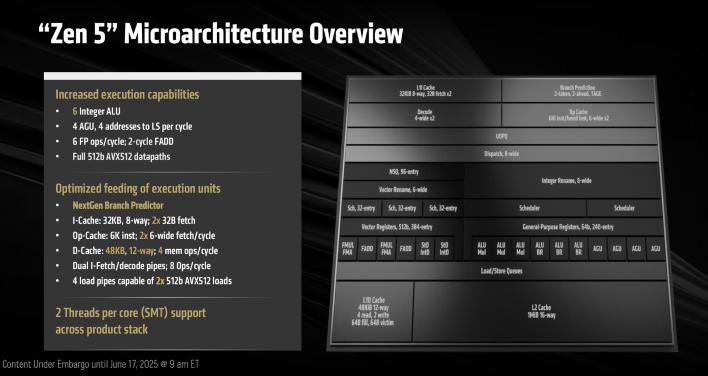
위 슬라이드에는 Zen 5가 제공하는 기능의 요약이 설명되어 있습니다. Zen 5는 개선된 페치 및 디코드, 더 넓어진 디스패치 및 실행 엔진, 증가된 캐시 대역폭 덕분에 더 높은 IPC를 제공합니다. 정수, 부동 소수점 및 벡터 연산에서도 발전이 이루어졌습니다.
Zen 5는 또한 Zen 4보다 낮은 지연 시간을 가진 더 나은 분기 예측 기능을 갖추고 있습니다. 이 아키텍처는 더 정교하고 정확한 TAGE(TAgged GEometric) 예측 알고리즘을 활용하는 듀얼 디코드 파이프라인을 특징으로 합니다. 명령어 캐시 지연 시간과 대역폭도 개선되었습니다.
이 아키텍처는 Zen 4의 6-wide에 비해 8-wide 디스패치/리타이어 엔진을 특징으로 하며, 6개의 ALU(3개의 곱셈기)와 새로운 통합 ALU 스케줄러 설계를 갖추고 있습니다. 반면 이전 Zen 아키텍처는 각 ALU마다 고유한 스케줄러를 가졌습니다. 결과적으로, Zen 5는 최대 448개의 미처리 작업을 지원할 수 있는 40% 더 큰 실행 창을 가집니다. 이 아키텍처는 본질적으로 더 많은 명령어를 처리하고 예측 실패로부터 더 잘 복구할 수 있습니다.
AMD는 또한 Zen 5의 데이터 캐시를 50% 확대(32KB 대 48KB)하고 L1 캐시와 FPU로의 최대 대역폭을 두 배로 늘렸습니다. Zen 5는 48KB 12-way L1 데이터 캐시를 특징으로 하지만, 더 높은 용량에도 불구하고 낮은 지연 시간을 유지하기 위해 4사이클 로드를 유지합니다. L2에서 L1으로의 대역폭도 Zen 4에 비해 두 배가 되었습니다.
Zen 4에서 AVX-512는 256비트 데이터 청크를 더블 펌핑하여 구현되었으므로, 512비트 AVX-512 워크로드는 두 개의 256비트 청크로 분해되어 엔진을 통과했습니다. 그러나 Zen 5는 완전한 512비트 너비의 데이터 경로를 특징으로 합니다. Zen 5의 FP/벡터 연산 장치는 FADD 명령어에 대해 2사이클의 지연 시간을 갖는 6개의 파이프라인을 특징으로 하며, 이는 Zen 4의 3사이클에서 감소한 것입니다. 또한 더 많은 수의 진행 중인 FP 명령어를 처리할 수 있습니다.
과거에 여러 번 언급했듯이, Zen 5 코어는 Zen 4에 비해 평균 16%의 IPC 향상을 제공합니다. 이는 비슷한 클럭 속도에서 더 나은 단일 스레드 성능으로 이어지며, 종합적으로 보면 다중 스레드 성능도 이러한 향상이 여러 코어에 걸쳐 확장되면서 개선됩니다.

스레드리퍼 9000, 기존 메인보드에서 작동
스레드리퍼 9000 시리즈 프로세서는 sTR5 소켓을 특징으로 하는 기존 WRX90 및 TRX50 플랫폼에 바로 장착하여 호환됩니다. 아마도 프로세서와 함께 일부 새로운 메인보드가 출시될 것이지만, 기술적으로 필수는 아닙니다 – 기존 보드는 바이오스/UEFI 업데이트 후 작동할 것입니다.

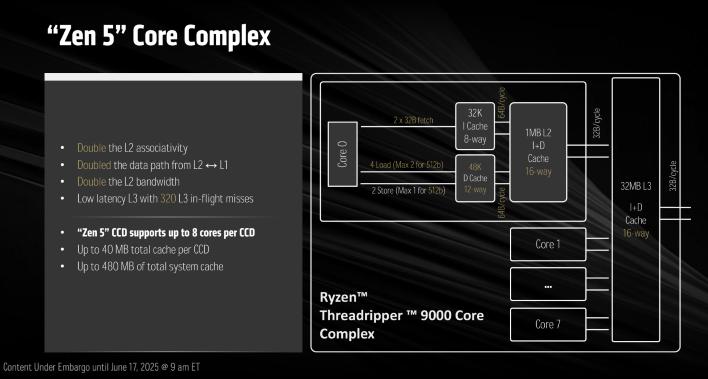
WRX90 메인보드에서 사용될 때, 스레드리퍼 Pro 9000WX 프로세서는 최대 8채널 메모리로 구성할 수 있으며, 총 148개의 PCIe 레인을 특징으로 하고, 이 중 144개가 사용 가능하며 128개는 PCIe Gen 5입니다. TRX50 HEDT 플랫폼은 4채널 메모리와 총 92개의 PCIe 레인(88개 사용 가능, 48개 PCIe 5)으로 최대 성능을 발휘합니다. 두 플랫폼 모두 스레드리퍼 7000 시리즈처럼 DDR5 RDIMM이 필요하지만, 더 빠른 속도가 공식적으로 지원될 것입니다.

메모리 기능 측면에서 스레드리퍼 Pro 9000WX 프로세서는 최대 2TB의 시스템 메모리를 DDR5-6400 데이터 속도까지 지원하여, 8채널 구성에서 최대 410GB/s의 피크 대역폭을 제공합니다. 비-Pro HEDT 스레드리퍼 9000의 경우, 최대 4개의 메모리 채널 때문에 피크 대역폭은 절반으로 줄어듭니다. 그러나 오버클러킹을 통해 더 높은 속도를 사용할 수 있으며, 플랫폼은 빠르고 쉬운 구성을 위해 AMD EXPO 메모리 프로파일을 지원할 것입니다.
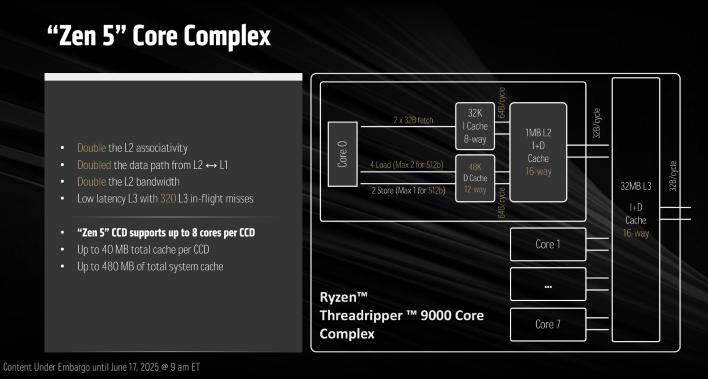
스레드리퍼 Pro 9000WX 시리즈는 또한 AMD의 "Pro" 보안 및 관리 기술을 제공한다는 점에서 일반 HEDT 제품과 다릅니다. 실제 빌드와 패키징도 다릅니다. 아래 이미지에서 볼 수 있듯이, 스레드리퍼 Pro 9000WX는 4개의 추가 컴퓨팅 다이를 가지고 있습니다. HEDT 부품은 코어가 비활성화된 동일한 부품이 아니라, 실제로 해당 코어를 위한 컴퓨팅 다이가 없습니다.
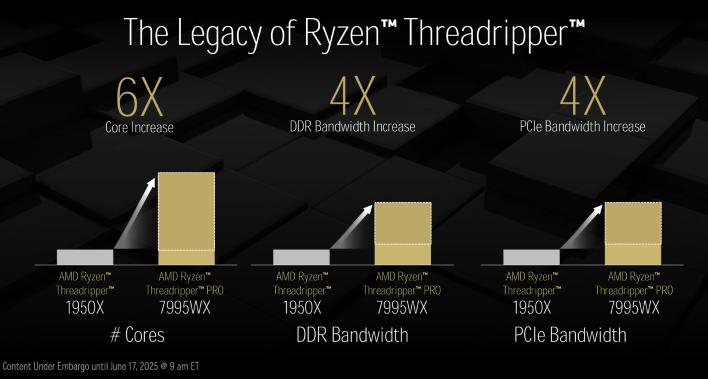
이 최신 스레드리퍼는 이전 세대 라인업과 마찬가지로 96코어 192스레드까지 확장됩니다; 주요 차이점은 스레드리퍼 9000 시리즈가 AMD의 Zen 5 아키텍처를 기반으로 한다는 것입니다.


HEDT 부품에서 AMD는 세 가지 모델을 선보였습니다. 최상위 모델은 Ryzen 스레드리퍼 9980X로, 64코어/128스레드 칩이며 3.2GHz 기본 클럭, 최대 5.4GHz 부스트 주파수, 그리고 256MB의 L3 캐시를 포함한 320MB의 넉넉한 총 캐시를 자랑합니다. 다음은 32코어, 64스레드의 Ryzen 스레드리퍼 9970X입니다. 이 제품은 4GHz 기본 클럭, 5.4GHz 최대 부스트 클럭, 128MB의 L3 캐시, 160MB의 총 캐시를 갖추고 있습니다. 마지막으로 24코어, 48스레드의 Ryzen 스레드리퍼 9960X는 4.2GHz 기본 클럭, 최대 5.4GHz 최대 부스트 클럭, 128MB의 L3 캐시, 152MB의 총 캐시를 갖추고 있습니다.
HEDT 부품에서 AMD는 세 가지 모델을 선보였습니다. 최상위 모델은 Ryzen 스레드리퍼 9980X로, 64코어/128스레드 칩이며 3.2GHz 기본 클럭, 최대 5.4GHz 부스트 주파수, 그리고 256MB의 L3 캐시를 포함한 320MB의 넉넉한 총 캐시를 자랑합니다. 다음은 32코어, 64스레드의 Ryzen 스레드리퍼 9970X입니다. 이 제품은 4GHz 기본 클럭, 5.4GHz 최대 부스트 클럭, 128MB의 L3 캐시, 160MB의 총 캐시를 갖추고 있습니다. 마지막으로 24코어, 48스레드의 Ryzen 스레드리퍼 9960X는 4.2GHz 기본 클럭, 최대 5.4GHz 최대 부스트 클럭, 128MB의 L3 캐시, 152MB의 총 캐시를 갖추고 있습니다.


HEDT 모델이 64코어 128스레드에서 정점을 찍는 반면, Pro 9000 WX 시리즈는 훨씬 더 높게 확장됩니다. 플래그십 모델은 Ryzen 스레드리퍼 Pro 9995WX로, 96코어, 192스레드, 2.5GHz 기본 클럭, 최대 5.4GHz 부스트 주파수, 거대한 384MB의 L3 캐시, 그리고 480MB의 총 캐시를 갖추고 있습니다. 스펙트럼의 다른 쪽 끝에는 Ryzen 스레드리퍼 Pro 9945WX가 있으며, 12코어, 24스레드, 4.2GHz 기본 클럭, 최대 5.4GHz 부스트 클럭, 64MB의 L3 캐시, 152MB의 총 캐시로 구성된 보다 온건한 구성을 특징으로 합니다.
스레드리퍼 9000 예상 성능
예상 성능 수준에 대해, AMD는 이전 세대 스레드리퍼와 인텔의 Xeon W 워크스테이션 프로세서와 비교한 상당한 양의 데이터를 제시했습니다.
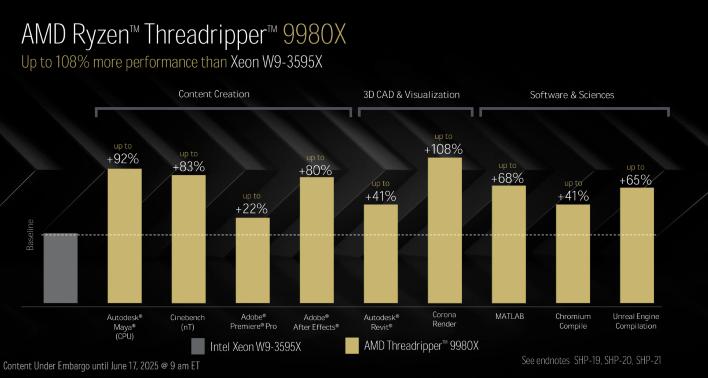
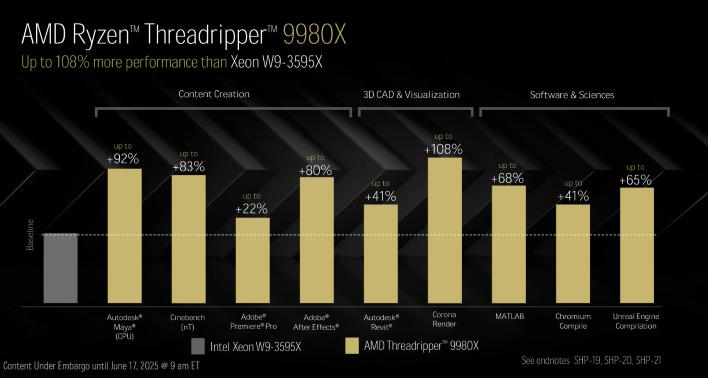
이 비교는 64코어 HEDT 스레드리퍼 9980X를 인텔의 60코어 Xeon w9-3595X와 비교한 것임에 유의하십시오. 보시다시피, 성능 향상은 다양하지만 엄청날 수 있으며, 스레드리퍼는 때때로 두 배 이상의 성능을 제공할 수 있습니다.
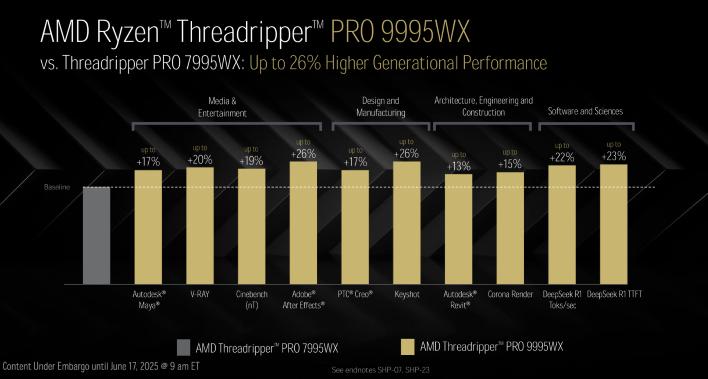
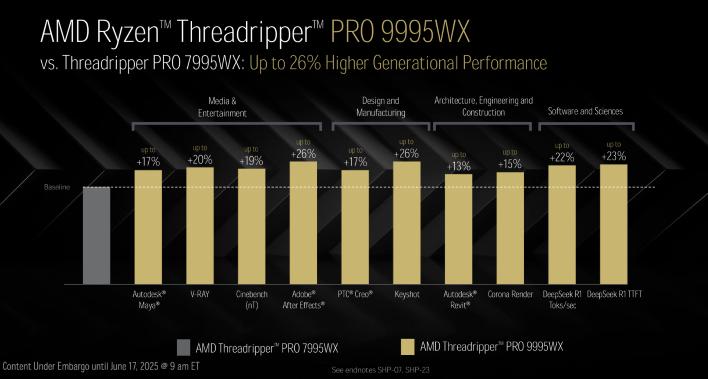
이제 일부 스레드리퍼 Pro 비교입니다. 비슷한 코어 수를 가진 이전 세대 스레드리퍼 Pro 7995WX와 비교했을 때, 곧 출시될 스레드리퍼 Pro 9995WX는 다중 스레드 워크로드에서 최대 26% 더 높은 성능을 제공합니다. 우리는 반응성 및 단일 스레드 워크로드에서도 개선을 기대합니다.
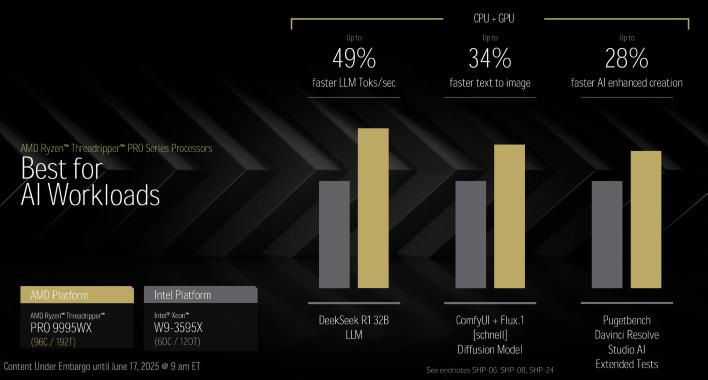
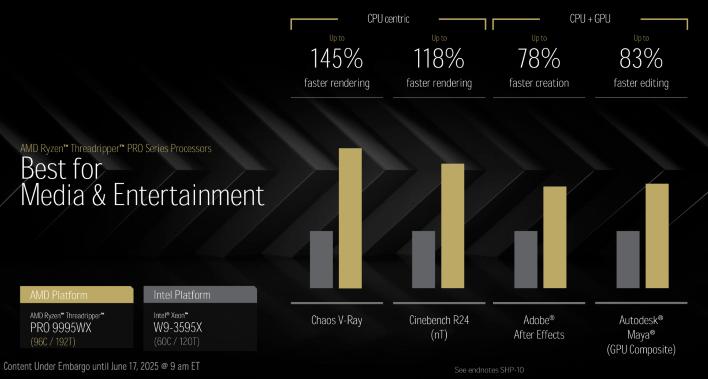
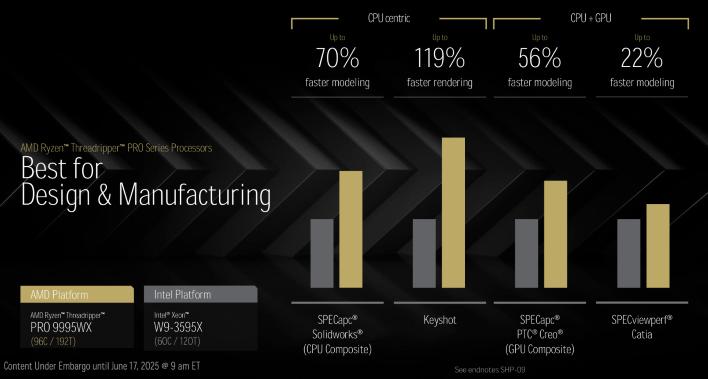
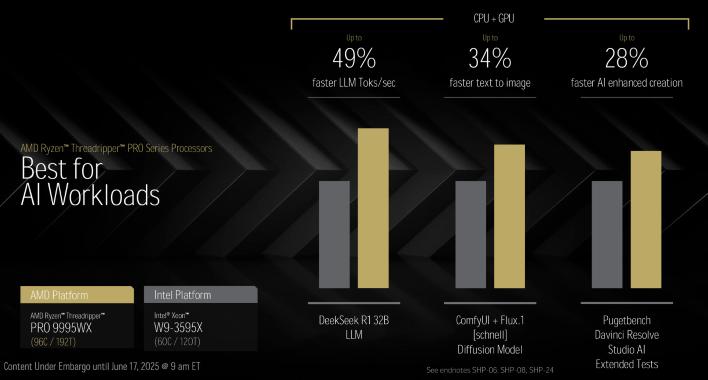
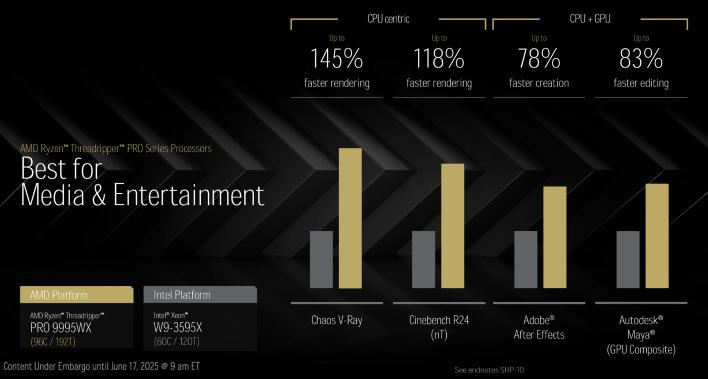
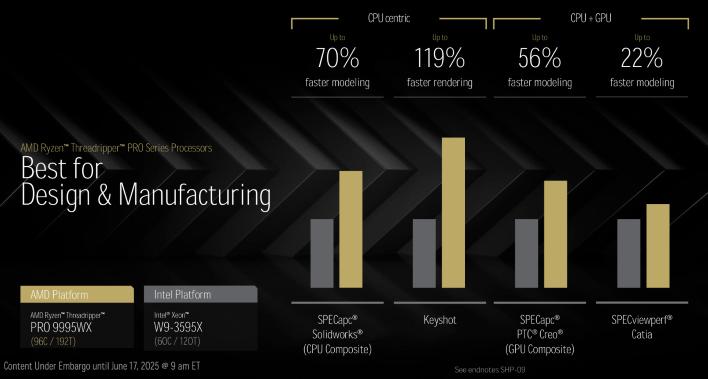
96코어 스레드리퍼 Pro 9995WX를 인텔의 최고 Xeon W 프로세서와 비교하면, 스레드리퍼 Pro는 훨씬 더 앞서 나갑니다. AMD의 수치에 따르면, 디자인 작업, 미디어 제작 또는 AI/ML 워크로드 등 어떤 작업에서든 새로운 스레드리퍼 Pro는 현재 최고급 Xeon W를 가볍게 제압합니다. 향후 새로운 스레드리퍼를 리뷰할 기회가 생긴다면, 이 수치들 중 일부를 검증해 보려고 합니다.
AMD Radeon AI Pro 9700: 엔지니어와 프로 비주얼라이제이션을 위한 RDNA 4

이제 Radeon AI Pro 9700으로 넘어가겠습니다. 핵심적으로, Radeon AI Pro 9700은 소비자 등급의 Radeon RX 9070 XT와 유사하지만, 두 배의 메모리를 갖춘 완전히 다른 보드 설계를 특징으로 하여 Pro-Visual 및 AI 워크로드에 훨씬 더 적합합니다.
Radeon AI Pro 9700은 RDNA 4 기반 Navi 48 GPU를 중심으로 제작되었습니다. 이 GPU는 각각 8개의 워크그룹 프로세서를 갖춘 4개의 셰이더 엔진으로 배열되어 있으며, 각 워크그룹 프로세서에는 2개의 컴퓨트 유닛이 장착되어 있습니다. 이는 이전 세대인 RDNA 3 GPU와 유사한 구조이지만, 성능과 효율성을 개선하고 새로운 기능을 추가하는 많은 아키텍처 개선 사항이 있습니다.

각 CU 내에는 RDNA 3의 피크 처리량의 2배를 제공하는 업데이트된 3세대 레이 액셀러레이터가 있습니다. RDNA 4의 레이 액셀러레이터는 개선된 BVH 압축, 가속화된 레이 트래버설 및 셰이딩, 그리고 Oriented Bounding Boxes라는 기능 지원을 추가하여 레이 교차율을 두 배로 높였습니다. 3세대 매트릭스 액셀러레이터도 존재하며, 개선된 성능과 함께 구조적 희소성(structured sparsity) 지원을 포함한 8비트 부동 소수점 데이터 유형에 대한 지원을 제공합니다. RDNA 4는 AI/ML 워크로드에 더 적합하며 추가 데이터 유형을 지원합니다.
이 GPU는 총 2MB의 CU 캐시와 8MB의 L2 캐시, 그리고 메모리 컨트롤러와 셰이더 엔진 사이의 가장자리에 위치한 64MB의 3세대 인피니티 캐시를 특징으로 합니다. L2 캐시는 향상된 패킷 가속 기능을 갖춘 업데이트된 중앙 위치의 커맨드 프로세서를 둘러싸고 있습니다. 업데이트된 커맨드 프로세서는 또한 일부 새로운 명령어를 지원하며, 데이터 페치를 더 잘 예측하고 캐시 활용률을 높이기 위해 개선된 분기 예측 기능을 갖추고 있습니다.
Radeon AI Pro 9700에서 GPU는 256비트 인터페이스(4개의 4x16 메모리 컨트롤러)를 통해 20Gbps의 유효 데이터 속도로 작동하는 32GB의 GDDR6 메모리에 연결됩니다. 메모리 컨트롤러는 또한 사용 가능한 대역폭을 더 잘 활용하기 위해 향상된 메모리 압축 기술을 특징으로 합니다.

Radeon AI Pro 9700은 총 64개의 CU, 64개의 레이 액셀러레이터, 128개의 AI(매트릭스) 액셀러레이터를 갖춘 Navi 48 GPU의 전체 구현을 특징으로 합니다. 약 2.9GHz의 부스트 클럭과 300와트의 총 보드 전력으로 최대 1,531 피크 TOPs(희소성을 가진 Int4)를 제공합니다. 참고로 이는 Radeon RX 9070 XT보다 약간 낮은 수치입니다.
듀얼 미디어 엔진과 업데이트된 Radiance 디스플레이 엔진도 GPU에 존재합니다. 실제로 미디어 및 디스플레이 엔진에는 여러 업데이트가 있으며, 게임/그래픽 관련 업데이트에 대한 훨씬 더 자세한 내용이 있지만, 전체 내용을 보려면 RDNA 4 심층 분석 기사를 읽으셔야 합니다. 오늘 분석에서 다루기에는 너무 많은 내용이 있습니다.
이전 Radeon Pro 카드와는 큰 차이점으로, AMD는 파트너사가 Radeon AI Pro 9700 카드를 시장에 출시할 수 있도록 허용하기로 결정했습니다. AMD는 가용성을 넓히고 자사의 Pro 하드웨어 및 소프트웨어를 더 넓은 범위의 고객에게 제공하기 위해 이러한 조치를 취했습니다. AMD는 또한 파트너와 협력하여 ROCm 및 Radeon에서 새로운 비즈니스를 개발하기를 희망합니다.
Radeon AI Pro 9700 예상 성능
더 빠른 메모리와 최신 아키텍처를 갖춘 Radeon AI Pro 9700은 이전 세대 Radeon Pro 카드에 비해 상당한 성능 향상을 제공할 것입니다.

이 GPU는 일부 데이터 유형에서 최대 4배 더 많은 TOPs를 제공하지만, FP32 성능 면에서 Radeon AI Pro 9700은 Radeon Pro W7800보다 약간 더 성능이 높을 뿐입니다.

그러나 비슷한 양의 메모리를 가지고도, 곧 출시될 Radeon AI Pro 9700은 RDNA 3 기반 Radeon Pro에 비해 초당 토큰 수 면에서 큰 성능 향상을 제공할 수 있습니다. 그리고 Radeon RX 9070 XT 리뷰에서 보았듯이, Navi 48 GPU는 이전 세대 Radeon에 비해 렌더링 및 게임에서도 큰 향상을 제공합니다.
워크스테이션을 위한 AMD 스레드리퍼 9000 및 Radeon AI Pro: 핵심 요약

스레드리퍼 9000 및 Radeon AI Pro 9000 시리즈는 아직 판매되지 않으며, 이번 분기 후반에 시장에 출시될 예정입니다. 하지만 이들이 출시되면, 우리는 매우 좋은 결과를 기대하고 있습니다. Zen 5로 스레드리퍼를 업그레이드하는 것은 전반적인 성능과 효율성 향상을 의미하며, RDNA 4는 한동안 AMD의 가장 흥미로운 GPU 아키텍처 중 하나였습니다.
Zen 5와 RDNA 4를 소비자 시장에서 성공으로 이끈 모든 요소들이 전문가용 워크스테이션으로 오고 있으며, 우리는 AMD가 많은 성공을 거둘 것으로 기대합니다. 물론 최종 판단은 제품을 실제로 테스트할 때까지 보류하겠지만, 현 시점에서는 전망이 매우 밝아 보입니다.
--------------------------------------------------------------------------------------광고(Advertising)--------------------------------------------------------------------------------------------------------

 Satechi USB4 슬림 NVMe SSD 외장...
Satechi USB4 슬림 NVMe SSD 외장...
 KDE Plasma 6.4 데스크톱 환경 공식 출...
KDE Plasma 6.4 데스크톱 환경 공식 출...


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}